Hace tres meses le propuse a un cliente algo que le sonó a ciencia ficción: que el agente iba a leer el ticket de Jira, implementar la feature, abrir el navegador para testearla, hacer el code review y crear el PR en GitHub. Que él solo tendría que revisar y aprobar.
Su respuesta fue "sí, claro". Con la misma energía con la que alguien te dice "ajá" cuando no te está escuchando.
Lo puse en marcha. En la primera semana el agente cerró cuatro tickets de forma autónoma. El quinto lo paré yo a mitad porque se estaba inventando un requisito que no estaba en el ticket. Ajusté el prompt. El sexto salió limpio.
Esto no es el futuro. Es lo que puedes montar hoy con Claude Code, el MCP de Jira, el MCP de Chrome y un CLAUDE.md bien escrito. Y en este post te cuento exactamente cómo funciona el pipeline para automatizar el proceso de desarrollo con IA de principio a fin.
Un pipeline agentico de desarrollo es un flujo automatizado donde un agente de IA ejecuta de forma autónoma los pasos de implementación, testing y revisión de código a partir de un ticket, reduciendo la intervención humana al momento de aprobar el resultado.
El problema con el workflow de desarrollo tradicional
El ciclo habitual de un developer en un equipo tiene un patrón claro: leer el ticket, entender el contexto del código, implementar, escribir el test manual en el navegador, hacer el PR, esperar el code review, corregir los comentarios, mergear, rezar para que el CI pase.
Cada uno de esos pasos tiene rozamiento. Cambios de contexto. Interrupciones. El developer senior pasa entre un 20% y un 30% de su tiempo en tareas que no son escribir código: leer tickets, crear PRs, hacer reviews de código propio.
Con agentes, ese porcentaje puede recortarse a la mitad.
No estoy hablando de reemplazar al developer. Estoy hablando de eliminar la fricción mecánica para que el developer se quede con las decisiones que importan.
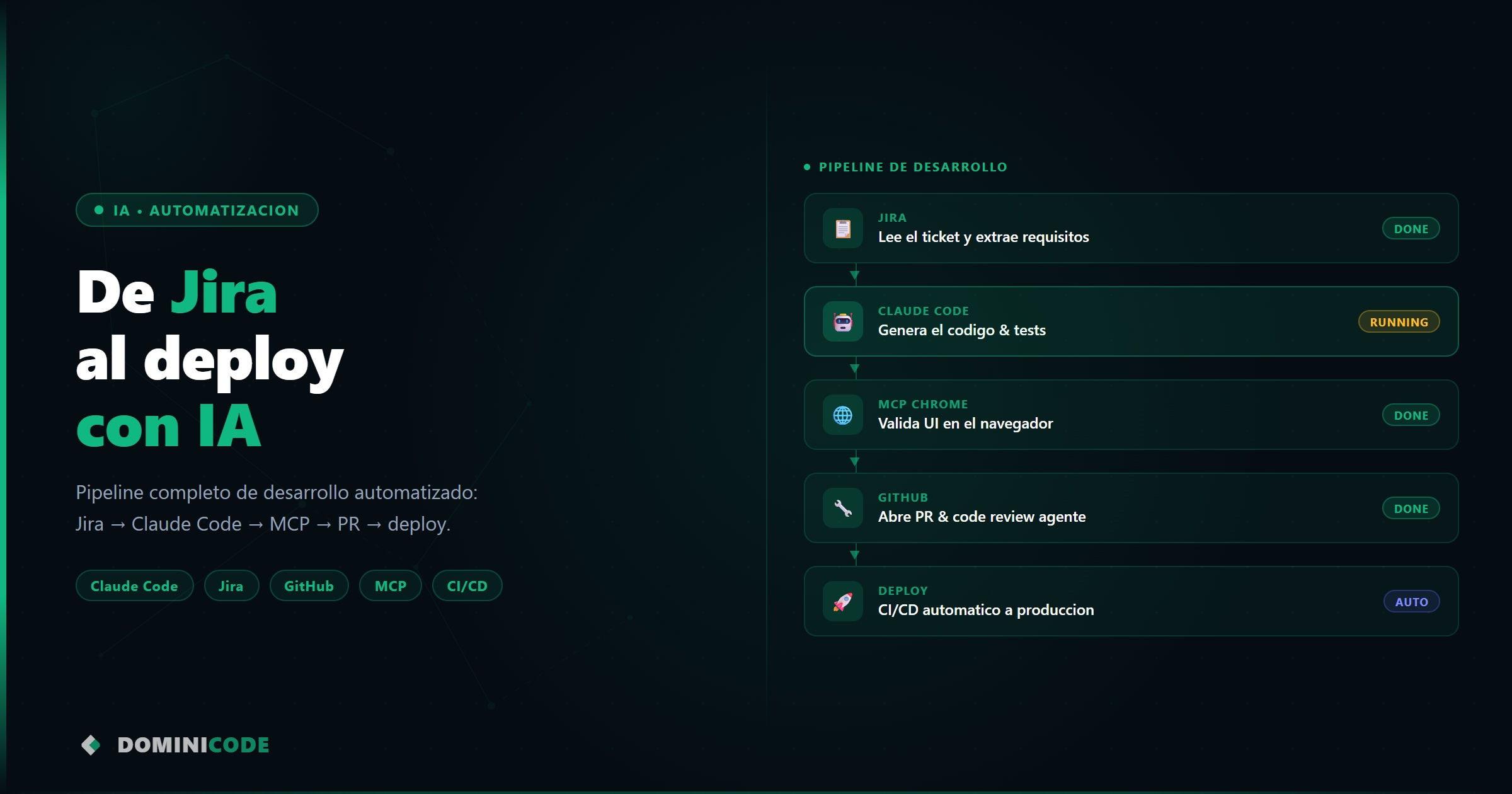
El pipeline completo: de Jira al deploy en seis pasos
Así es el flujo que tengo montado:
[Ticket Jira]
↓
[Claude Code lee ticket via MCP Jira]
↓
[Lee CLAUDE.md + contexto del proyecto]
↓
[Implementa la feature o bug fix]
↓
[MCP Chrome: abre navegador, navega, verifica]
↓
[/code-review: detecta problemas antes del merge]
↓
[Crea PR en GitHub con descripción del ticket]
↓
[CI/CD se dispara tras el merge]
↓
[Deploy a producción]
El developer entra en el paso de revisar el PR. Todo lo anterior lo hace el agente.
Paso 1: leer el ticket de Jira
Claude Code tiene acceso al MCP de Jira. Cuando invocas el agente con el ID del ticket, extrae la descripción, los criterios de aceptación, el tipo de tarea y cualquier comentario relevante.
# Invocar el agente con un ticket específico
claude "Lee el ticket PROJ-412 de Jira e implementa la tarea"
El agente extrae:
- Descripción de la tarea
- Criterios de aceptación (los usará para el testing)
- Labels y tipo (bug, feature, refactor)
- Comentarios con contexto adicional
Si los criterios de aceptación están mal escritos o son ambiguos, el agente lo detecta y puede preguntar antes de implementar. Ese comportamiento se configura en el CLAUDE.md del proyecto.
Paso 2: leer el contexto del proyecto con CLAUDE.md
El CLAUDE.md es la memoria del agente sobre tu proyecto. Antes de escribir una sola línea de código, Claude Code lee este archivo para entender:
- Convenciones de nomenclatura
- Arquitectura del proyecto (qué hace cada capa)
- Comandos para correr tests y el servidor local
- Patrones prohibidos o recomendados
- Cómo se estructuran los PRs en este equipo
Un CLAUDE.md bien escrito transforma al agente de "asistente genérico" a "developer que conoce el proyecto". La diferencia entre los dos es enorme en producción.
# CLAUDE.md — ejemplo mínimo
## Arquitectura
- Feature modules en `src/features/<nombre>/`
- Services solo en la capa de aplicación, nunca en componentes
- Todos los efectos secundarios pasan por el store (NgRx)
## Comandos importantes
- Dev server: `bun run dev`
- Tests: `bun run test`
- Build: `bun run build`
## Convenciones de PR
- Título: `[PROJ-XXX] descripción breve`
- Descripción: resumen del ticket + cambios técnicos + steps to test
Si quieres ver cómo construir un CLAUDE.md completo para un proyecto real, en el curso Construye con IA lo hago desde cero con un proyecto en TypeScript.
Paso 3: implementar la feature
Claude Code implementa la tarea. Lee los archivos relevantes, sigue las convenciones del CLAUDE.md, escribe los tests unitarios si el proyecto los requiere y ejecuta el servidor local para verificar que compila sin errores.
Aquí es donde el contexto importa más que el modelo. Un agente con buen contexto (CLAUDE.md + ticket detallado) implementa con una tasa de acierto mucho más alta que uno que empieza desde cero.
El agente también puede hacer preguntas aclaratorias antes de implementar si detecta ambigüedad. Ese comportamiento se configura así en el CLAUDE.md:
## Comportamiento del agente
- Si los criterios de aceptación son ambiguos, pregunta antes de implementar
- No inventes requisitos que no estén en el ticket
- Si necesitas crear un nuevo módulo, describe la estructura antes de crearla
Paso 4: testing en el navegador con el MCP de Chrome
Este es el paso que más sorprende a los developers cuando lo ven por primera vez.
El MCP de Chrome (servidor MCP que usa Playwright por debajo para controlar el navegador) le da a Claude Code control total: abrir URLs, hacer clic en elementos, rellenar formularios, tomar screenshots, leer el contenido del DOM, verificar mensajes de error en consola.
El agente usa los criterios de aceptación del ticket como guión de testing. Si el ticket dice "el usuario debe poder filtrar la tabla por fecha y ver solo los registros del rango seleccionado", el agente:
- Abre la app en
localhost:4200 - Navega a la sección de la tabla
- Selecciona un rango de fechas
- Verifica que los registros mostrados coinciden con el filtro
- Toma un screenshot del resultado
- Revisa la consola del navegador para detectar errores
// API de Playwright que ejecuta el servidor MCP internamente
await page.goto('http://localhost:4200/dashboard/reports');
await page.click('[data-testid="date-filter"]');
await page.fill('[data-testid="date-from"]', '2026-01-01');
await page.fill('[data-testid="date-to"]', '2026-01-31');
await page.click('[data-testid="apply-filter"]');
const rows = await page.$$('[data-testid="table-row"]');
// Verifica que todos los rows tienen fechas dentro del rango
Si algo falla, el agente lo reporta, corrige el código y vuelve a ejecutar el test. Es un loop de implementar → testear → corregir que el developer antes hacía manualmente.
Referencia: Playwright — documentación oficial de automatización de navegadores.
Paso 5: code review automático antes del PR
Antes de crear el PR, el agente ejecuta /code-review — un slash command de Claude Code que analiza todos los cambios del diff:
- Detecta problemas de seguridad (inputs sin sanitizar, secrets hardcodeados)
- Verifica que se siguen las convenciones del proyecto
- Revisa cobertura de casos edge
- Detecta código duplicado o patrones que el equipo tiene como prohibidos
Si el code review detecta problemas críticos, el agente los corrige antes de crear el PR. Si son sugerencias menores, las incluye como comentarios en la descripción del PR para que el reviewer humano las evalúe.
Tengo un post completo sobre cómo configurar el agentic code review con Claude Code si quieres profundizar en esa parte del pipeline.
Paso 6: crear el PR y disparar el CI/CD
El agente crea el PR en GitHub con:
- Título siguiendo la convención del proyecto (extraído del ticket)
- Descripción generada del ticket: contexto, criterios de aceptación, cambios técnicos
- Screenshot del testing en navegador como evidencia visual
- Checklist de testing para el reviewer
# El agente ejecuta esto internamente
gh pr create \
--title "[PROJ-412] Filtro por fecha en tabla de reportes" \
--body "$(cat pr-description.md)" \
--base main
Cuando el developer aprueba el PR y hace el merge, el CI/CD se dispara automáticamente. GitHub Actions corre los tests, valida el build y despliega a producción. El agente ya no interviene en este paso — el pipeline de CI/CD es responsabilidad del equipo de infraestructura.
Lo que el developer sigue haciendo
Dejar claro este punto porque es importante: el agente no reemplaza al developer. El developer hace tres cosas:
- Escribir tickets con criterios de aceptación claros. Esto es ahora la habilidad más valiosa. Un ticket ambiguo produce código ambiguo.
- Revisar y aprobar el PR. El agente implementa, pero el developer decide si el resultado es correcto.
- Mantener el CLAUDE.md actualizado. Las convenciones del proyecto, la arquitectura, los patrones — el agente es tan bueno como el contexto que le das.
El rol evoluciona de "el que escribe el código" a "el que define qué construir y valida que se construyó bien". Que es, paradójicamente, donde está el valor real de un developer senior.
En Dominicode Labs estamos implementando este pipeline en proyectos reales con la comunidad — si quieres ver el setup completo con errores incluidos, es donde lo hacemos en directo.
Cómo empezar a automatizar tu proceso de desarrollo con IA
No montes el pipeline completo de golpe. Empieza con esto:
- Escribe un CLAUDE.md sólido para tu proyecto
- Instala el MCP de GitHub en Claude Code
- Prueba crear un PR automático desde un cambio pequeño
- Añade el MCP de Chrome y testea un flujo simple en el navegador
- Conecta Jira cuando los pasos anteriores funcionen de forma estable
El pipeline completo lleva tiempo afinar. El valor llega antes de tenerlo completo.
Preguntas frecuentes
¿El MCP de Chrome funciona con cualquier framework frontend (React, Vue, Angular)?
Sí. El MCP de Chrome opera sobre el navegador real, no sobre el framework. No le importa si la app está en Angular, React o Vue — interactúa con el DOM resultante. Solo necesitas que la app esté corriendo en un servidor local accesible.
¿Qué pasa si los criterios de aceptación del ticket están mal escritos o son incompletos?
El agente intentará inferir la intención, pero si la ambigüedad es suficientemente alta, puede preguntar antes de implementar o implementar algo que no era lo esperado. La calidad del output del agente es directamente proporcional a la calidad del input (el ticket). Invertir en escribir buenos tickets es la palanca más subestimada de este pipeline.
¿Se puede usar este pipeline sin Jira? ¿Con Linear, GitHub Issues u otras herramientas?
Sí. Claude Code tiene MCPs para Linear, Asana y GitHub Issues. El principio es el mismo: el agente lee el ticket desde la fuente, extrae los criterios de aceptación y los usa como guión de implementación y testing. La integración específica depende del MCP disponible para cada herramienta.
¿Es seguro dejar que el agente tenga acceso a la base de datos o a servicios externos durante el testing?
No. El testing del agente debe hacerse contra un entorno de desarrollo o staging, nunca contra producción ni contra una base de datos con datos reales. El CLAUDE.md debe especificar explícitamente contra qué entorno corre el agente y qué permisos tiene. El principio de mínimos privilegios aplica igual para agentes que para cualquier proceso automatizado.
¿Cuánto tiempo lleva montar este pipeline desde cero?
El pipeline mínimo (CLAUDE.md + MCP GitHub + PR automático) puede estar funcionando en un día. El pipeline completo con MCP de Jira, MCP de Chrome y code review automático lleva entre una semana y dos de ajuste para que funcione de forma estable en un proyecto real. La mayor parte del tiempo se va en escribir un CLAUDE.md completo y en afinar los prompts para que el agente entienda las convenciones del proyecto.
Si quieres aprender a construir con IA desde cero hasta producción, echa un vistazo al curso Construye con IA.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.
Leave a Reply