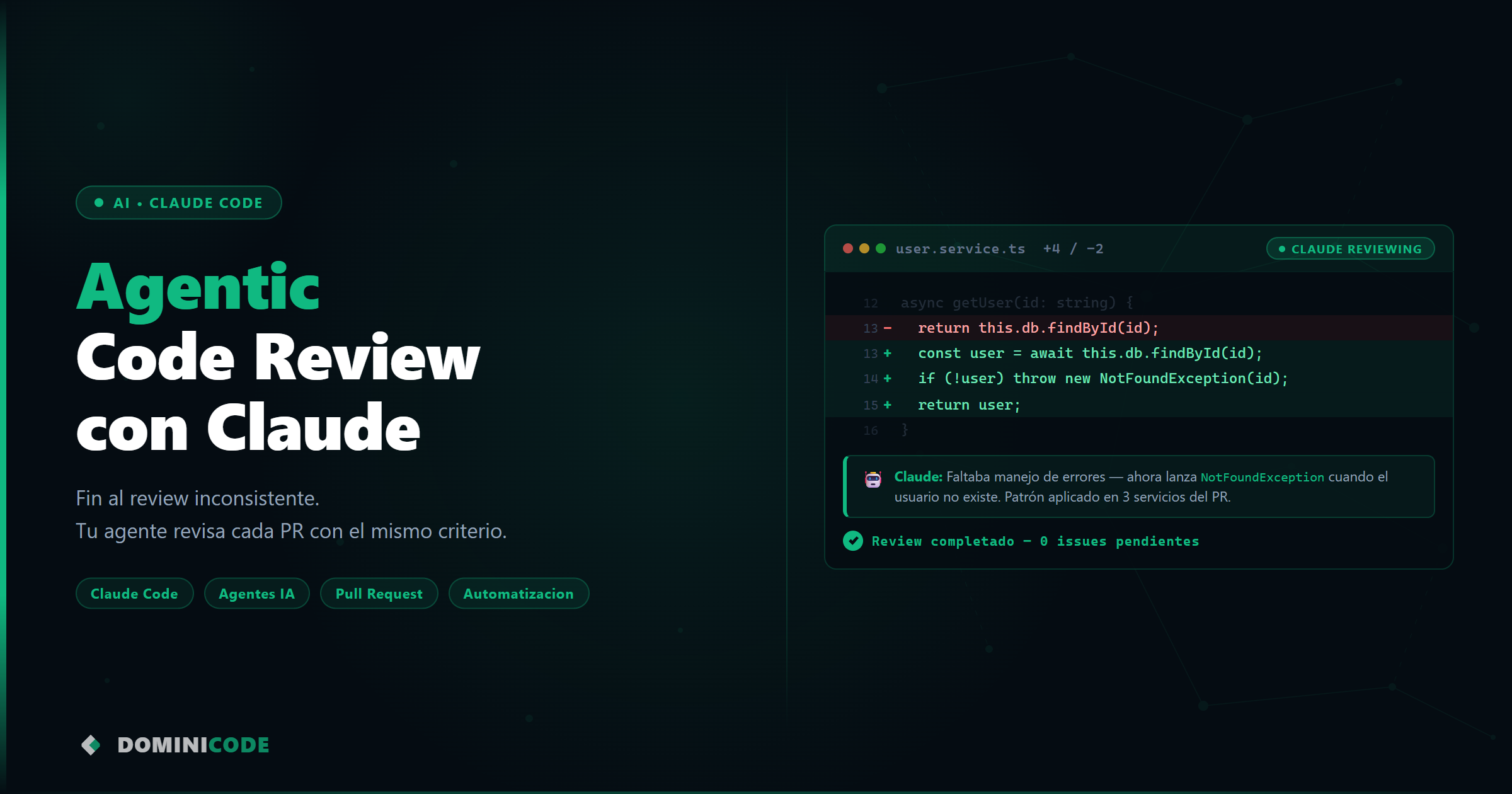
Llevaba tres horas implementando un sistema de autenticación con JWT cuando me di cuenta de que no había especificado nada.
¿El token debía expirar en la sesión o persistir entre reinicios? ¿Qué pasaba cuando el refresh token vencía estando el usuario activo? ¿El endpoint de logout invalidaba en servidor o solo limpiaba el cliente?
Yo respondí esas preguntas sobre la marcha. Sin coherencia, sin registro de decisiones. El código resultó funcional pero arquitectónicamente un desastre.
Eso no es un problema del agente. Es un problema de proceso. Para eso existe sdd-creator.
El problema de codear sin especificar
Los agentes de IA son extremadamente buenos ejecutando instrucciones. También son extremadamente buenos ejecutando instrucciones mal definidas — y el resultado es lo que imaginas.
Cuando le das a Claude Code o a Cursor un prompt del tipo “implementa login con JWT”, el agente toma decisiones. Muchas. Las toma rápido, sin preguntarte, porque así trabajan. El output es código funcional que responde a una interpretación del problema, no necesariamente a tu interpretación.
El fallo no está en la IA. Está en que nunca estableciste qué querías exactamente.
Spec-Driven Development (SDD) resuelve esto con una premisa simple: antes de generar código, genera el spec. Un documento que responde qué hace la feature, por qué existe, quién la usa, qué flujos cubre y bajo qué criterios está terminada.
El problema es que hacer bien un spec lleva disciplina. Y cuando tienes el agente abierto y las ganas de construir, la tentación de saltártelo es enorme.
Qué es sdd-creator y cómo funciona
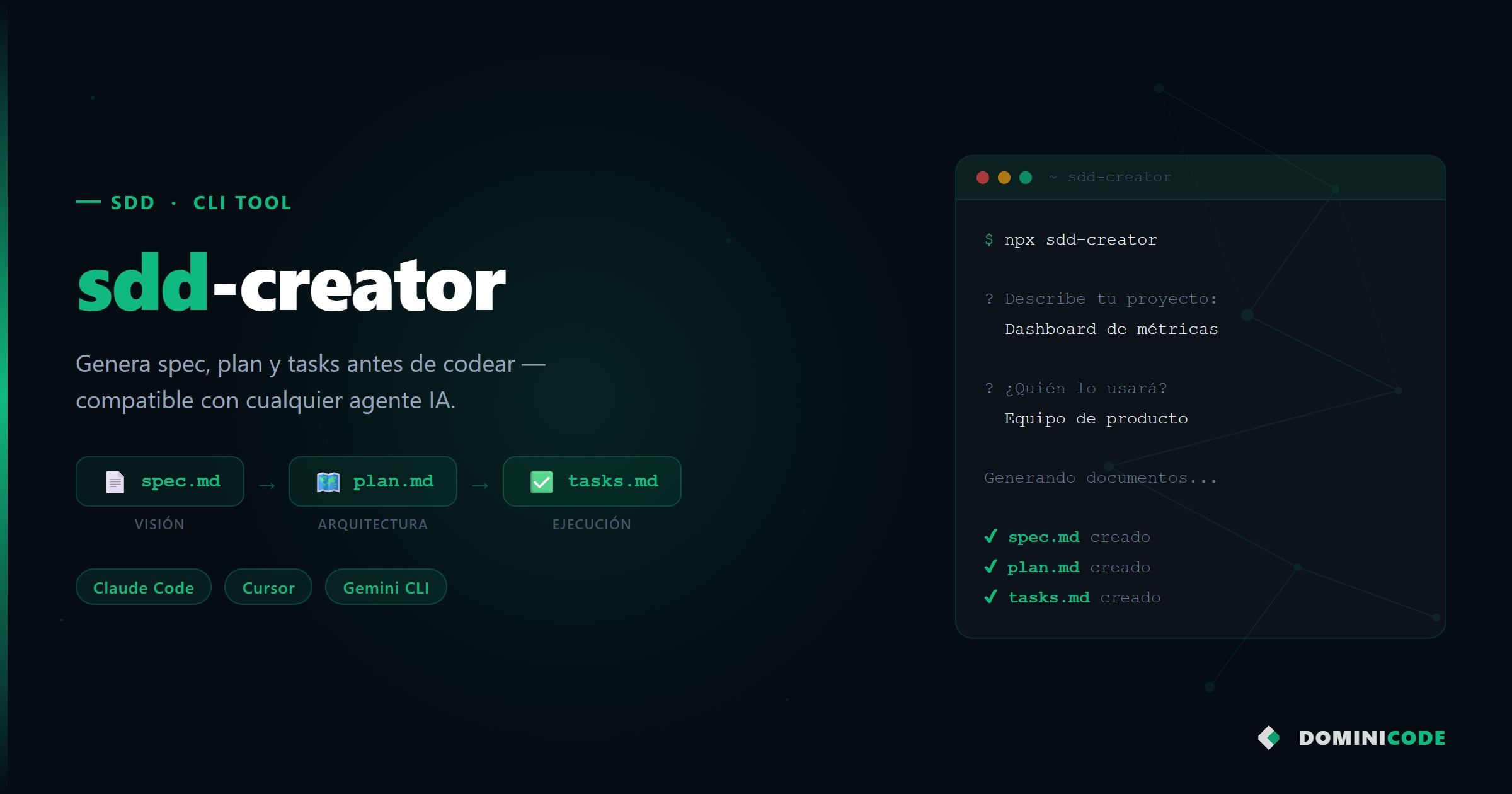
sdd-creator es un skill para agentes de IA que impone el proceso de especificación antes de ejecutar cualquier implementación. No es un generador de documentos — es un interrogador. El agente no escribe código hasta que el spec esté completo y confirmado.
A diferencia de pedirle directamente al agente que “genere un spec libre”, sdd-creator impone siempre las mismas 6 secciones y bloquea la implementación hasta recibir confirmación explícita. Sin esa estructura, los specs se convierten en párrafos de texto libre que el agente interpreta como quiere.
El flujo tiene siete pasos:
- Describes el feature o proyecto que quieres construir
- sdd-creator detecta la complejidad (LOW / MEDIUM / HIGH)
- Te hace una entrevista interactiva — te pregunta lo que no especificaste
- Genera
spec.mdcon 6 secciones estructuradas - Espera tu confirmación antes de continuar
- Genera
plan.mdcon las decisiones técnicas y la planificación por fases - Genera
tasks.mdcon las tareas ordenadas para TDD — y solo entonces empieza la implementación
El repositorio está en GitHub: bezael/sdd-creator — MIT, v1.2.0.
Si quieres entender la metodología detrás con más profundidad, el libro SDD cubre los principios completos, con patrones reales de proyectos en producción.
Instalación
Una sola línea:
npx skills@latest add bezael/sdd-creatorEl CLI detecta tu herramienta y copia el skill al directorio correcto automáticamente. Como referencia, los directorios destino son:
- Claude Code:
~/.claude/skills/ - Cursor:
.cursor/rules/del proyecto
No hay configuración adicional. No hay API keys. No hay dependencias de runtime. El skill vive como un archivo de instrucciones que el agente carga en contexto cuando lo invocas.
Para instalación manual o integración con otros agentes, consulta la documentación oficial de Claude Code o los docs de tu herramienta.
Tutorial paso a paso — feature de login con JWT
Vamos con un ejemplo concreto. Tienes una app NestJS y quieres implementar autenticación con JWT. Sin sdd-creator, abres el agente y escribes: “implementa autenticación con JWT”. Con sdd-creator, el proceso es diferente.
Paso 1 — Invoca el skill
En Claude Code o en Cursor, activa sdd-creator. Luego describe tu feature:
Quiero implementar un sistema de autenticación con JWT para una API NestJS.
Incluye registro, login, refresh de token y logout.Paso 2 — La entrevista interactiva
sdd-creator detecta complejidad media y empieza a preguntarte:
- ¿El token de acceso expira en cuánto tiempo?
- ¿El refresh token se invalida en servidor o solo en cliente?
- ¿El endpoint de logout invalida todos los dispositivos activos o solo el actual?
- ¿La app requiere rate limiting en los endpoints de auth?
- ¿Los usuarios pueden tener múltiples sesiones simultáneas?
Preguntas incómodas. Preguntas que el agente habría respondido solo — con su mejor criterio — si no le hubieras forzado a preguntarte.
Paso 3 — Confirmas el spec.md
El agente genera el spec.md completo. Lo revisas, corriges lo que no cuadra, y confirmas. Solo entonces avanza.
Paso 4 — plan.md y tasks.md
sdd-creator genera el plan técnico (decisiones de arquitectura, librerías, estructura de módulos) y la lista de tareas ordenadas para TDD. Primero los tests de los casos de error — token expirado, credenciales inválidas, refresh token revocado. Luego el código que los hace pasar.
Resultado: el agente implementa exactamente lo que especificaste. Sin sorpresas. Sin decisiones implícitas. Sin “lo hice así porque parecía razonable”.
Los 3 archivos que genera
spec.md — La especificación en 6 secciones
La estructura es fija e invariable:
- Visión — qué problema resuelve y por qué existe esta feature
- Usuarios — quién la usa y cuáles son sus necesidades reales
- Funcionalidades — qué puede hacer el sistema (listado concreto)
- Flujos — cómo se comporta el sistema en los escenarios principales
- Arquitectura — cómo está organizado técnicamente
- NFRs — requisitos no funcionales: performance, seguridad, disponibilidad
La estructura fija es deliberada. Cuando el spec siempre tiene las mismas 6 secciones, puedes revisarlo en segundos y saber exactamente qué falta. Un spec libre en prosa no tiene esa propiedad.
Si quieres ver cómo aplicar estas 6 secciones en un proyecto greenfield completo, este post sobre SDD con slices verticales lo cubre en detalle.
plan.md — Las decisiones técnicas
El plan responde: ¿cómo vamos a construir esto? Librerías seleccionadas y por qué. Estructura de módulos. Fases de implementación. Dependencias entre componentes. Riesgos identificados.
No es un documento académico — es el registro de las decisiones que tomarías antes de empezar, aunque fueran en tu cabeza. Externalizar ese razonamiento tiene valor: el agente lo usa como referencia durante la implementación, y tú lo usas para hacer review.
tasks.md — La lista ordenada para TDD
Las tareas están ordenadas para Test-Driven Development. Los tests de los contratos del sistema van primero. El código que los satisface, después. Cada tarea es atómica — una sola responsabilidad, verificable por sí sola.
Cuando tienes esta lista, puedes darle una tarea al agente y pedirle que haga solo esa. Sin divagar. Sin añadir “mejoras” que no pediste. La tarea acotada, con su test, con su criterio de aceptación.
Esta es exactamente la forma de trabajar que desarrollamos en el curso Construye con IA — de la idea al producto real, con agentes IA y sin perder el control del código.
Cuándo NO usar sdd-creator
sdd-creator añade valor cuando el problema tiene suficiente complejidad para merecer una especificación. Hay casos donde el overhead no compensa:
- Scripts de un solo uso: automatizaciones de 20-30 líneas que se ejecutan una vez y se descartan
- Prototipos desechables: experimentos para validar si algo es técnicamente posible, sin intención de iterar sobre el código
- Hotfixes triviales: corregir un typo, cambiar un color, ajustar un literal de texto
La regla práctica: si el feature va a producción y va a ser mantenido, usa sdd-creator. Si es exploración o descarte, ve directo al código.
Compatible con cualquier agente de IA
sdd-creator no está atado a un agente específico. Funciona con todos los entornos de desarrollo con IA más usados:
| Agente | Tipo de integración | Directorio |
|---|---|---|
| Claude Code | Skills nativo | ~/.claude/skills/ |
| Cursor | Rules | .cursor/rules/ del proyecto |
| Codex CLI (OpenAI) | AGENTS.md / system prompt | Configuración de proyecto |
| Gemini CLI | System prompt | Configuración de proyecto |
| Aider | Contexto personalizado | .aider.conf.yml |
| Continue | config.json | .continue/ |
El formato MIT también significa que puedes adaptarlo a tu equipo. Si tienes convenciones de nomenclatura propias, o secciones adicionales en tus specs, puedes forkear el repositorio y ajustarlo.
FAQ
¿Qué es sdd-creator?
sdd-creator es un skill para agentes de IA que implementa el flujo de Spec-Driven Development. Cuando lo activas, el agente no escribe código directamente — primero te hace una entrevista para entender el problema, luego genera tres documentos estructurados (spec.md, plan.md, tasks.md), y solo después implementa. Es la diferencia entre darle instrucciones a un agente y darle una especificación.
¿Con qué agentes de IA funciona sdd-creator?
Con Claude Code, Cursor, Codex CLI (OpenAI), Gemini CLI, Aider y Continue. El skill es un archivo de instrucciones, no una integración específica — cualquier agente que soporte archivos de contexto puede usarlo. La instalación varía: en Claude Code se copia a ~/.claude/skills/, en Cursor va a .cursor/rules/.
¿Cuánto tiempo lleva generar la spec con sdd-creator?
Entre 5 y 20 minutos, dependiendo de la complejidad del feature. Una feature simple puede especificarse en 5 minutos. Una feature con múltiples flujos, integraciones externas y requisitos de seguridad puede tomar 20. Ese tiempo es siempre menor que el que cuesta refactorizar código que el agente implementó sin especificación.
¿Es sdd-creator compatible con proyectos legacy?
Sí. SDD no requiere empezar desde cero — puedes aplicarlo feature a feature sobre una base de código existente. El spec refleja las restricciones reales del sistema existente: qué puedes cambiar, qué no, y qué deuda técnica tienes que tener en cuenta durante la implementación.
¿Puedo usar sdd-creator en equipos?
Sí, y es donde más valor aporta. El spec.md generado es el contrato de la feature — cualquier miembro del equipo puede revisarlo, cuestionarlo y aprobarlo antes de que empiece la implementación. Elimina el “yo entendí que…” de las reuniones de review.
Ahora, cuando tengo el agente abierto y las ganas de construir, lo primero que activo es sdd-creator. Los 15 minutos de spec se pagan solos. Esas tres horas de JWT no se van a repetir.
Si quieres ver cómo SDD encaja en el ciclo completo de desarrollo con IA — desde la idea hasta el producto desplegado — en Dominicode Labs tienes acceso a proyectos reales donde aplicamos este flujo de principio a fin.
Por Bezael Pérez — Fundador de Dominicode.