Un tech lead me escribió hace unas semanas con una pregunta que no esperaba: “Bezael, ¿cómo le demuestro a mi CTO que la IA está funcionando?”
El equipo llevaba tres meses usando GitHub Copilot y Claude Code. Los developers estaban contentos. Las entregas se sentían más rápidas. Pero cuando llegó el momento de justificar la licencia ante dirección, el tech lead no tenía un solo número sólido que presentar.
El CTO le preguntó lo de siempre: “¿Cuántas líneas de código más estáis produciendo?”
Y ahí empezó el problema.
Medir la productividad en equipos que usan IA requiere sustituir métricas de output (líneas de código, tickets cerrados) por métricas de flujo y calidad: cycle time, ciclos de revisión por PR, defect escape rate y confianza del equipo. Sin ese cambio de marco, los datos dicen que la IA no funciona cuando en realidad el problema es la regla con la que mides.
El error de medir lo que siempre has medido
Las métricas tradicionales de productividad —líneas de código, tickets cerrados por sprint, commits por semana— no estaban diseñadas para un equipo que delega trabajo a una IA.
Cuando un developer usa Claude Code para generar el esqueleto de un servicio, los tickets no cambian. Los commits pueden ser los mismos. Pero el tiempo que ese developer tardó en llegar a ese commit pasó de cuatro horas a cuarenta minutos.
Eso no aparece en ningún dashboard de Jira.
El problema no es que la IA no mejore la productividad. El problema es que medir la productividad en equipos que usan IA con métricas de 2015 produce datos que no dicen nada, o peor, datos que contradicen lo que el equipo siente que está pasando.
Y cuando los datos no cuentan la historia real, la dirección toma decisiones basadas en una historia falsa.
Por qué las métricas tradicionales fallan con IA
Hay tres razones concretas por las que las métricas clásicas se rompen en cuanto entra la IA.
Primera: la unidad de medida cambia. Antes, un developer hacía una cosa a la vez. Con IA, puede mantener contexto de tres o cuatro tareas en paralelo. Los tickets cerrados por semana pueden ser los mismos, pero la complejidad por ticket se multiplica.
Segunda: el trabajo invisible desaparece. La IA absorbe el trabajo de bajo valor — boilerplate, documentación inicial, tests unitarios básicos — que antes inflaba las métricas sin añadir valor real. Al desaparecer ese trabajo, las métricas caen aunque la productividad suba.
Tercera: la calidad pasa a ser la variable crítica. Un equipo con IA puede producir más código en menos tiempo. Pero si ese código no está bien especificado, va a producir más código malo en menos tiempo. Las métricas de velocidad no capturan esto. El ciclo de revisión, sí.
| Métrica tradicional | Por qué falla con IA |
|---|---|
| Líneas de código | No refleja el tiempo ahorrado en generación automática |
| Tickets cerrados por sprint | No captura el aumento de complejidad por ticket |
| Commits por semana | El mismo número, pero con 10x menos tiempo de escritura |
| Velocidad de sprint (story points) | Se mantiene estable aunque la dificultad técnica suba |
Las métricas que sí funcionan para medir productividad con IA
Estas son las cinco métricas que tienen sentido cuando el equipo trabaja con asistencia de IA. No son nuevas — algunas vienen del marco DORA, otras son adaptaciones directas. Lo nuevo es el contexto en que las usas.
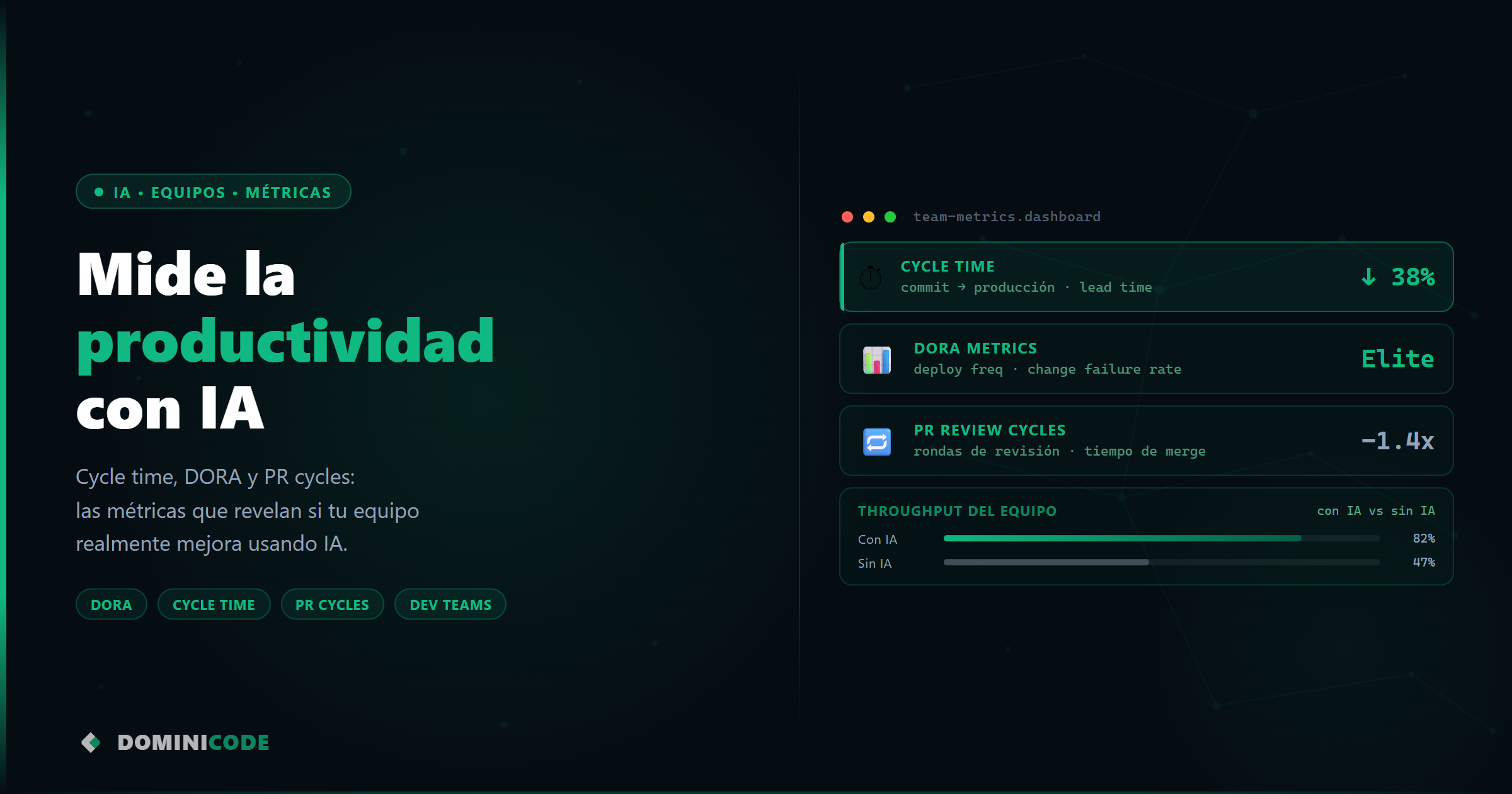
1. Cycle time por tarea (tiempo de ciclo real)
Mide cuánto tiempo pasa desde que una tarea entra en “en progreso” hasta que está en “revisión”. No en “cerrada” — en revisión. Ese delta captura la velocidad de producción antes de que el proceso de PR y QA añada ruido.
Si el equipo usa IA y el cycle time no baja, hay un problema de especificación o de prompting, no de herramienta.
2. PR review cycles (iteraciones por pull request)
Cuántas veces vuelve un PR del revisor al autor. Con IA, el código puede ser correcto sintácticamente pero incorrecto semánticamente — hace lo que el prompt pedía, no lo que el ticket decía. Un aumento en ciclos de revisión es la primera señal de que el equipo está usando IA sin un proceso de especificación previo. Si quieres entender por qué la especificación es la clave aquí, el post sobre vibe coding sin sistema lo explica desde el ángulo del proyecto completo.
Benchmark útil: según datos de LinearB y el SPACE framework de Microsoft Research, un equipo sano sin IA tiene entre 1,2 y 1,8 ciclos de revisión por PR. Con IA bien implementada, debería bajar a menos de 1,2.
3. Defect escape rate (bugs que llegan a producción)
El número de bugs que pasan el proceso de revisión y llegan a producción. La IA genera código con menos bugs de sintaxis pero puede introducir errores de lógica más sutiles cuando el contexto está mal definido. Esta métrica captura si la calidad real del output está subiendo o bajando.
4. Time to first meaningful contribution (tiempo al primer output de valor)
Cuánto tarda un developer nuevo —o uno que empieza en una nueva área del código— en hacer su primera contribución significativa. Con IA, este tiempo debería caer drásticamente porque los modelos actúan como documentación interactiva del codebase. Si no cae, el equipo no está usando IA para onboarding.
5. Developer-reported confidence score (autoconfianza técnica)
Una encuesta semanal de una pregunta: “Del 1 al 10, ¿cómo de seguro te has sentido tomando decisiones técnicas esta semana?” No mide lo que el developer produce — mide si la IA lo está empoderando o creando dependencia. Una caída sostenida en esta métrica es una alarma: el equipo está delegando decisiones que no debería delegar.
Cómo implementar estas métricas en tu equipo
No necesitas una plataforma nueva. Con lo que ya tienes, puedes empezar esta semana.
- Extrae cycle time de tu gestor de tareas actual. Linear, Jira y Notion tienen este dato. Calcula la media de los últimos tres sprints antes de implementar IA. Eso es tu baseline.
- Añade un campo “ciclos de revisión” a tu flujo de PRs. En GitHub puedes automatizarlo con un simple script que cuente las veces que un PR pasa a “changes requested” y vuelve a “review”. No necesitas nada sofisticado.
- Activa el tracking de bugs por origen. ¿El bug vino de código generado con IA o de código escrito a mano? Añadir esa etiqueta a los issues de producción durante dos meses te da datos que nadie más tiene en tu organización.
- Envía el confidence score cada viernes. Un Google Form de una pregunta. Anónimo. Cinco minutos de setup. Los datos que obtienes en ocho semanas son más útiles que cualquier encuesta de engagement anual.
- Revisa las cinco métricas cada dos semanas, no cada sprint. El impacto de la IA no es lineal al principio. Los primeros cuatro sprints suelen mostrar un plateau o incluso una caída mientras el equipo ajusta workflows. La mejora real aparece en la semana seis o siete.
Errores comunes al medir productividad con IA
Error 1: medir demasiado pronto. Implementar IA y medir el impacto al sprint siguiente no funciona. El equipo necesita entre cuatro y seis semanas para ajustar su forma de trabajar con los modelos. Medir antes genera datos negativos que no reflejan el potencial real.
Error 2: medir al individuo en lugar de al equipo. “¿Cuánto usa la IA este developer?” es la pregunta equivocada. La adopción de IA es un comportamiento social — si el tech lead no la usa, el equipo no la usa. Mide adopción a nivel de equipo, no de persona.
Error 3: ignorar el coste de contexto. La IA produce output rápido, pero alguien tiene que escribir el prompt, revisar el output y decidir qué parte usar. Ese tiempo no aparece en los tickets. Si no lo contabilizas, tus métricas de velocidad quedan artificialmente infladas en comparación con el coste real.
Error 4: no tener un baseline previo. Es imposible demostrar mejora sin un punto de partida. Antes de dar acceso a la IA al equipo, captura dos sprints de datos de cycle time, PR cycles y defect rate. Sin eso, cualquier número que presentes es opinión, no evidencia.
Error 5: confundir actividad con impacto. El número de prompts enviados a un LLM no es una métrica de productividad. Es una métrica de uso. El impacto se mide en los outputs que importan: tiempo de entrega, calidad del código, confianza del equipo.
Preguntas frecuentes
¿Qué métricas DORA son las más relevantes cuando el equipo usa IA?
Las cuatro métricas DORA —deployment frequency, lead time for changes, change failure rate y time to restore service— siguen siendo válidas, pero el contexto cambia. Con IA, el “lead time for changes” debería bajar significativamente porque la fase de escritura de código se acelera. Si no baja, el cuello de botella está en el proceso de revisión o en la especificación, no en el coding. La “change failure rate” es la que más debes vigilar: un aumento aquí con IA activa indica que el equipo está delegando contexto que los modelos no tienen — exactamente lo que explicamos en el post sobre context engineering para proyectos con IA.
¿Cuánto tiempo tarda en verse el impacto real de la IA en productividad?
En la mayoría de equipos que he visto, los primeros resultados medibles aparecen entre las semanas seis y ocho. Las primeras cuatro semanas son de ajuste: el equipo aprende qué delegar, qué especificar antes de delegar, y cómo revisar output de IA. A partir de la semana ocho, el cycle time baja y la autoconfianza sube de forma sostenida.
¿Cómo justifico ante dirección el coste de las licencias de IA si las métricas tardan en mostrarse?
El argumento más sólido no son las métricas de productividad — es el coste de oportunidad. Un developer senior en España cuesta entre 50.000 y 80.000 euros al año. Si la IA reduce su ciclo de desarrollo un 30%, el retorno de una licencia de 20 euros al mes se justifica en las primeras dos horas de uso. Presenta ese cálculo antes de presentar las métricas.
¿Vale la pena usar herramientas específicas de medición de productividad IA como Uplevel o Faros?
Para equipos de más de quince developers, sí. Estas plataformas integran datos de GitHub, Jira y Slack para calcular métricas de flujo de trabajo con granularidad que un tracker manual no puede dar. Para equipos menores, el setup de estas herramientas consume más tiempo del que ahorran. Empieza con las métricas manuales descritas en este post y migra a plataformas dedicadas cuando el equipo supere los veinte developers.
¿El confidence score realmente sirve o es demasiado subjetivo?
Es subjetivo por diseño. Las métricas objetivas miden el output. El confidence score mide el proceso interno del developer: si está tomando decisiones con criterio o si está dependiendo de la IA para decisiones que debería tomar él. Un developer que valora su confianza en 4 sobre 10 de forma sostenida no está usando IA como amplificador — la está usando como muleta. Eso es información que ningún dashboard de GitHub te da.
Lo que puedes hacer mañana
No esperes a tener el sistema perfecto. Esta semana, haz una sola cosa: calcula el cycle time medio del último sprint de tu equipo. Ese número es tu baseline.
La próxima vez que alguien te pregunte si la IA está funcionando, tendrás un punto de referencia real en lugar de una sensación.
Si quieres ir más lejos — ver cómo integramos estas métricas dentro de un proceso estructurado de desarrollo con IA, de la especificación al deploy — en el curso Construye con IA trabajamos exactamente ese flujo: no solo usar la IA para escribir código, sino construir el sistema alrededor de ella para que los resultados sean medibles y repetibles.
Y si tu equipo ya está en ese punto y quieres ir más profundo, en Dominicode Labs tenemos recursos sobre workflows de desarrollo con IA, plantillas de tracking y acceso directo a la comunidad para resolver dudas en contexto.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.
Leave a Reply