Llevaba tres horas con el agente.
Tres horas corrigiendo. El agente seguía haciendo lo mismo: tomaba decisiones razonables para el contexto que tenía, pero el contexto que tenía era incompleto desde el principio. Yo le daba feedback, él ajustaba, y en la siguiente iteración el problema aparecía en otro sitio. Dos pasos adelante, uno y medio atrás.
No era el modelo. Era yo — y el problema era la ausencia de agentic engineering en mi flujo de trabajo.
No había planificado lo que quería construir antes de empezar. No había descompuesto el problema en piezas que el agente pudiera manejar sin ambigüedad. Le había dado un objetivo vago y esperado que el agente lo resolviera. Y el agente hacía lo que podía — que no era suficiente para lo que yo necesitaba.
Eso es lo que diferencia a alguien que usa agentic engineering de alguien que simplemente le pide cosas a la IA: un framework de trabajo. Un ciclo operativo que convierte la delegación caótica en colaboración sistemática.
El framework tiene cinco pasos: Plan → Steer → Decompose → Delegate → Systematize.
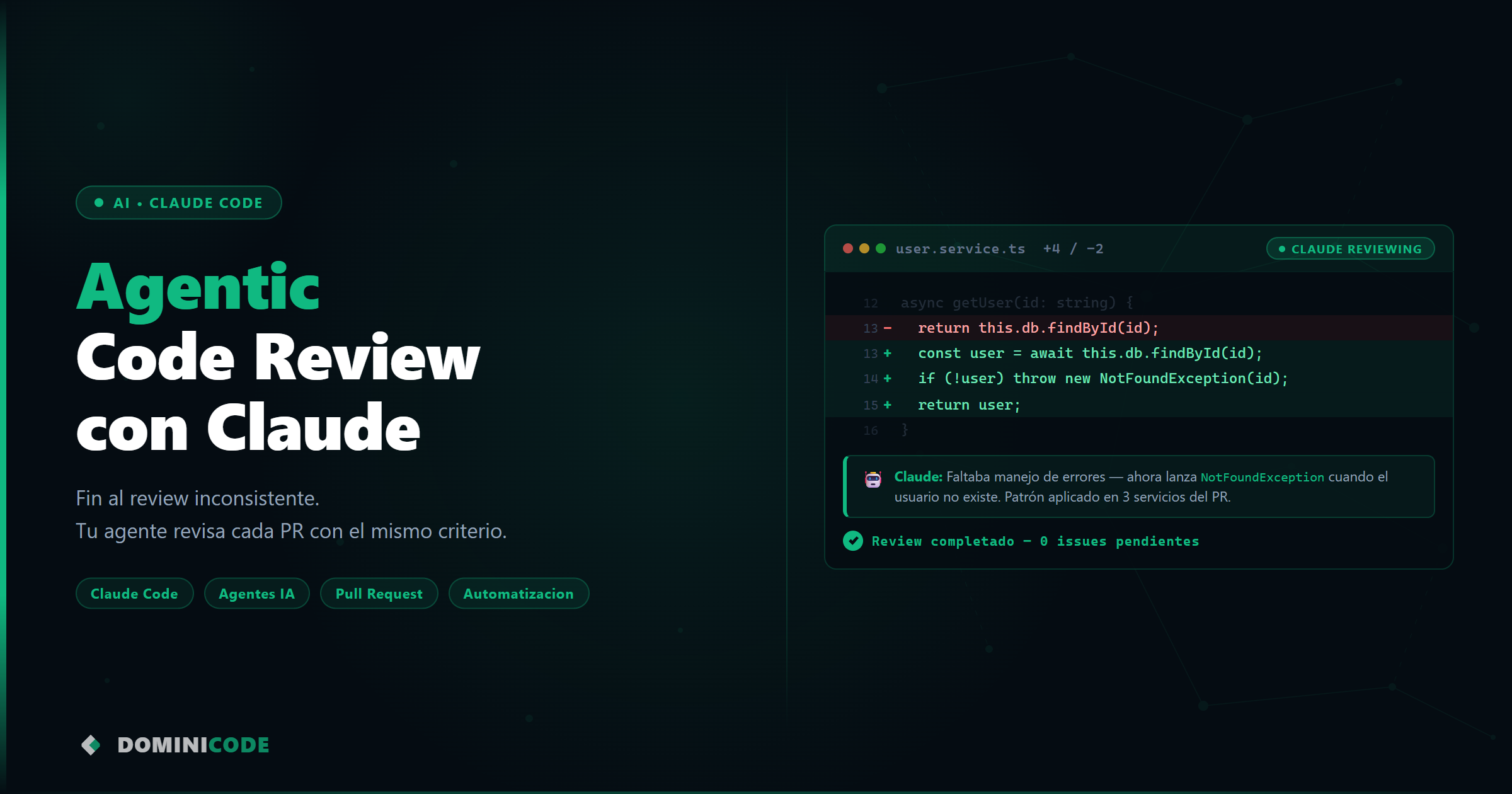
El agentic engineering es la disciplina de orquestar agentes de IA de forma sistemática — definiendo objetivos, descomponiendo problemas, delegando tareas con el contexto preciso y capturando los patrones que funcionan para reutilizarlos. Es la diferencia entre usar la IA como herramienta de texto y tratarla como un sistema de producción.
Por qué el prompting no es suficiente
Hay un malentendido que veo constantemente en developers que llevan meses usando IA sin resultados consistentes: creen que el problema es el prompt.
Mejoran el prompt. Añaden más contexto. Usan few-shot examples. Prueban otro modelo. Y los resultados mejoran marginalmente pero el problema de fondo persiste — siguen obteniendo outputs que tienen que reescribir, completar o corregir antes de poder usar.
El problema no es el prompt. Es que no hay agentic engineering en el proceso — están tratando al agente como un oráculo al que preguntas. Y los oráculos funcionan bien para respuestas, no para construcción.
Construir con IA no es preguntar. Es orquestar. Y orquestar requiere un proceso, no una técnica de redacción.
El framework de agentic engineering: los 5 pasos
| Paso | Objetivo | Señal de que lo estás haciendo bien |
|---|---|---|
| Plan | Define qué construir antes de abrir el editor | Tienes objetivo, contexto y criterios de éxito escritos |
| Steer | Guía la dirección durante la ejecución | Intervienes en los puntos de decisión, no en cada acción |
| Decompose | Rompe el problema en tareas atómicas y verificables | Cada tarea tiene bordes claros, sin decisiones implícitas |
| Delegate | Asigna la tarea correcta con el contexto mínimo necesario | El agente no necesita hacer preguntas para empezar |
| Systematize | Convierte lo que funciona en proceso repetible | Tienes CLAUDE.md, templates y hooks activos |
1. Plan — Define antes de abrir el editor
El Plan no es el prompt inicial. Es la decisión de qué quieres construir, para quién, con qué criterios de éxito, y qué contexto necesita el agente para no tener que improvisar.
La mayoría de los problemas de agentic engineering empiezan aquí — o mejor dicho, por saltarse este paso.
Cuando no hay Plan, el agente trabaja con hipótesis. Asume el stack que le parece más probable. Asume la arquitectura que ha visto más en su entrenamiento. Asume que los casos edge no existen porque no se los mencionaste. Y esas hipótesis se propagan a través de todo el trabajo posterior.
Un Plan mínimo tiene tres elementos:
Objetivo concreto — No "implementa el módulo de usuarios". Sí: "Implementa el endpoint POST /users que recibe { email, name }, valida con Zod, crea el registro en la tabla users de Supabase y devuelve { id, email, createdAt }. Error 409 si el email ya existe."
Contexto relevante — El stack, las convenciones de naming que ya usa el proyecto, las decisiones de arquitectura tomadas, las restricciones conocidas. Esto es lo que va en el CLAUDE.md del proyecto — no como documentación, sino como memoria estructurada que el agente lee al inicio de cada sesión.
Criterios de éxito — Cómo sabes que el agente terminó bien su trabajo. Tests que deben pasar. Comportamientos que debes poder demostrar. Sin criterios de éxito explícitos, "listo" significa cosas distintas para ti y para el agente.
El Spec-Driven Development es la metodología que formaliza este paso: especificar el sistema antes de construirlo, con contratos concretos que el agente puede implementar sin inventar.
2. Steer — Guías la dirección, no desapareces
El Steer es el feedback loop activo durante la ejecución.
Hay un patrón que veo repetidamente: el developer escribe un prompt elaborado, lanza el agente y vuelve veinte minutos después esperando encontrar la tarea completada. A veces funciona. Cuando no funciona, el agente ha pasado esos veinte minutos construyendo en la dirección equivocada con mucha confianza.
Steer no significa microgestionar. Significa estar presente en los puntos de decisión que importan.
La señal de que necesitas intervenir: el agente está a punto de tomar una decisión con consecuencias amplias sin haber pedido confirmación. Cambiar la estructura de un módulo. Renombrar una abstracción clave. Elegir entre dos arquitecturas posibles. Esos son los momentos en que tu presencia tiene más palanca.
En práctica, Steer implica:
- Revisar el output de las primeras iteraciones antes de que el agente avance demasiado
- Corregir la dirección cuando el agente toma una decisión incorrecta — y hacerlo en el momento, no cuando ya hay diez archivos afectados
- Hacer preguntas explícitas al agente sobre sus decisiones: "¿Por qué elegiste este enfoque sobre el alternativo?" — no para cuestionar todo, sino para verificar que el razonamiento es el correcto antes de comprometerte con esa dirección
El objetivo del Steer no es hacer el trabajo del agente. Es hacer que el agente haga el trabajo correcto. Sin Steer, el agentic engineering se convierte en delegación ciega — y la delegación ciega escala los errores, no los resultados.
3. Decompose — Rompe el problema en tareas atómicas
La Decompose es donde más se gana en calidad de output y donde menos developers invierten tiempo.
Un agente que recibe "implementa el sistema de autenticación completo" toma demasiadas decisiones implícitas. Qué estrategia de sesiones. Qué campos en el token. Cómo manejar el refresh. Qué pasa cuando el token expira durante una request. Cada una de esas decisiones tiene consecuencias, y el agente las toma sin consultarte porque no sabe que importan.
La descomposición transforma decisiones implícitas en decisiones explícitas.
Una tarea bien descompuesta tiene estas características:
Atómica — Se puede completar en una sola sesión sin depender de otras tareas que no estén terminadas.
Sin ambigüedad en los bordes — Define qué entra, qué sale y cómo interactúa con lo que ya existe. "Implementa el endpoint de login que recibe { email, password } y devuelve { accessToken, refreshToken, user } usando el servicio AuthService ya existente" — eso es una tarea sin ambigüedad en los bordes.
Verificable — Al terminar puedes saber con certeza si la tarea está bien hecha o no. Si no puedes verificar, la tarea está mal definida.
// Tarea mal definida — demasiado scope, demasiadas decisiones implícitas
// "Implementa el sistema de autenticación con JWT y manejo de sesiones"
// Tarea bien definida — atómica, verificable, bordes claros
// "Implementa la función generateTokenPair(userId: string): Promise<TokenPair>
// que genera accessToken (15min) y refreshToken (7d) firmados con RS256.
// TokenPair = { accessToken: string; refreshToken: string; expiresAt: Date }
// Usa la clave privada de process.env.JWT_PRIVATE_KEY.
// Test: genera un par, verifica que accessToken expira correctamente."
La diferencia no está en la complejidad. Está en quién toma las decisiones.
4. Delegate — Asigna al agente correcto con el contexto mínimo necesario
Delegate es donde muchos developers confunden prompt engineering con delegación real.
Prompt engineering es refinar las instrucciones para obtener un output mejor del mismo agente. La delegación dentro del agentic engineering es asignar la tarea correcta al agente correcto con el contexto que necesita para ejecutarla — ni más ni menos.
Dos errores opuestos destruyen la delegación:
Delegación sin contexto suficiente. El agente no tiene acceso a las decisiones de arquitectura previas, no conoce las convenciones del proyecto, no sabe qué existe ya. El resultado es código que no encaja — funcionalmente correcto, arquitecturalmente incorrecto.
Delegación con contexto excesivo. Pegas en el prompt el README completo, los últimos cinco commits, tres archivos relacionados y la descripción del sistema entero. El modelo procesa todo ese contexto pero el ruido diluyente reduce la precisión. Más contexto no siempre es mejor contexto.
El contexto mínimo necesario es el que responde a: ¿qué necesita saber el agente para tomar las mismas decisiones que yo tomaría? No el contexto que me tranquiliza a mí — el que necesita el agente.
En Claude Code esto se traduce en ser deliberado sobre qué archivos mencionas explícitamente (@auth.service.ts, @user.schema.ts) y qué instrucciones incluyes en el CLAUDE.md del proyecto para que estén disponibles en cada sesión sin tener que repetirlas.
5. Systematize — Lo que funciona una vez se convierte en proceso
El Systematize es el paso que separa a los developers que mejoran semana a semana de los que repiten los mismos errores en cada proyecto nuevo.
Cuando un flujo de trabajo de agentic engineering funciona bien — un tipo de tarea, un patrón de prompt, una estructura de descomposición — el Systematize lo captura como proceso reutilizable. No como documentación que nadie leerá. Como artefacto operativo que puedes invocar directamente.
Tres formas concretas de systematizar:
CLAUDE.md por proyecto — Las decisiones de arquitectura, las convenciones, las restricciones del proyecto. Este archivo es la memoria del proyecto que persiste entre sesiones. Sin él, cada sesión nueva parte de cero.
Templates de tareas — Si descompones el mismo tipo de problema una y otra vez (endpoints REST, componentes Angular, tests de integración), el template captura la estructura de descomposición que ya demostró funcionar. No vuelves a pensar cómo descomponer — aplicas el template y ajustas los detalles.
Hooks y workflows — En Claude Code, los hooks de PreToolUse y PostToolUse permiten ejecutar validaciones automáticas antes o después de que el agente actúe. Un hook que ejecuta tsc --noEmit antes de cada escritura de archivo previene que el agente introduzca errores de tipos que luego tienes que depurar a mano. Automatizas la verificación, no solo la generación.
// .claude/settings.json — hook que valida TypeScript antes de escribir
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "npx tsc --noEmit 2>&1 | head -20"
}
]
}
]
}
}
El Systematize convierte el conocimiento tácito en proceso explícito. Y el proceso explícito escala — a proyectos futuros, a otros developers del equipo, a agentes que ejecutan workflows sin supervisión.
Cómo se conectan los 5 pasos en un ciclo
Los cinco pasos del agentic engineering no son lineales. Son un ciclo que se repite a dos escalas.
Escala de proyecto:
- Una vez al inicio: Plan global
- Primera Decompose en bloques grandes
- Primera ronda de Delegate al agente
- Steer durante la ejecución
- Systematize los patrones que funcionaron para el siguiente proyecto
Escala de tarea:
- Plan de la tarea concreta
- Decompose en subtareas si es necesario
- Delegate al agente con el contexto mínimo
- Steer durante la ejecución
- Systematize si el patrón vale la pena capturar
Lo que conecta los dos niveles es el contexto acumulado. Cada Systematize en una tarea pequeña alimenta el Plan del bloque siguiente. El CLAUDE.md que actualizas después de cada sesión hace que la siguiente sesión parta de un estado mejor que la anterior.
El ciclo se mejora a sí mismo. Eso es lo que distingue un sistema de una técnica.
Aplica el framework construyendo un producto real
Leer el framework es útil. Aplicarlo en un proyecto real con presión de tiempo y decisiones concretas es lo que lo hace tuyo.
El Workshop Beyond Prompts (https://workshop.dominicode.com/) del 9 de julio es exactamente eso: 3 horas donde aplicamos el agentic engineering construyendo un producto real con Claude Code — de idea a producto deployado usando Plan → Steer → Decompose → Delegate → Systematize en vivo. No es una clase magistral. Es una sesión de trabajo donde tomas decisiones, te equivocas, corriges y sales con un sistema que puedes replicar.
Si quieres prepararte antes del workshop, el curso Construye con IA: de la idea al producto con Claude Code cubre los fundamentos de agentic engineering con el mismo enfoque: criterio para cada decisión, no solo instrucciones que seguir.
Y si quieres trabajar el framework con proyectos concretos en comunidad — revisar tu arquitectura, discutir las decisiones que no están claras, ver cómo otros developers aplican estos pasos — en Dominicode Labs hacemos exactamente eso semana a semana.
FAQ
¿Cuál es la diferencia entre el agentic engineering y el Spec-Driven Development?
SDD es la metodología que cubre en detalle el paso Plan — cómo especificar un sistema antes de construirlo, con contratos y criterios de éxito concretos. El framework de agentic engineering Plan → Steer → Decompose → Delegate → Systematize es más amplio: cubre todo el ciclo de trabajo con agentes, desde antes de escribir la spec hasta capturar los patrones que funcionaron para reutilizarlos. SDD y agentic engineering son complementarios — SDD es la respuesta detallada a "cómo hacer bien el Plan".
¿El agentic engineering funciona con cualquier herramienta de IA o solo con Claude Code?
Los cinco pasos son agnósticos a la herramienta. La lógica de Plan, Steer, Decompose, Delegate y Systematize aplica igual si usas Claude Code, Cursor, Copilot o la API directamente. Lo que cambia son los artefactos concretos: en Claude Code el contexto persistente vive en CLAUDE.md y los hooks en .claude/settings.json; en Cursor vive en .cursor/rules/; en otros entornos en AGENTS.md. El framework es la estructura. Los artefactos son la implementación específica de cada herramienta.
¿Cuánto tiempo tarda implementar este framework en un proyecto que ya existe?
Para un proyecto existente sin ningún sistema, el mínimo viable —un CLAUDE.md básico con el stack y las convenciones principales, más una primera descomposición del backlog pendiente— tarda entre dos y cuatro horas. No es un proceso de migración completa. Es añadir las piezas que hacen que cada sesión futura sea más efectiva que las anteriores. El Systematize es acumulativo — mejora con el tiempo, no requiere estar completo desde el día uno.
¿El paso Steer no anula el beneficio de la autonomía del agente?
No. Steer es intervención en los puntos de decisión de alto impacto, no supervisión constante de cada acción. Un agente ejecutando tareas bien definidas puede trabajar durante decenas de ciclos sin necesitar tu input — eso es autonomía real. Steer te pide que estés presente cuando el agente enfrenta una bifurcación arquitectural, no cuando está implementando un endpoint que ya tiene todos los criterios claros. La diferencia práctica: Steer activo tarda minutos por sesión. Steer ausente puede costar horas de corrección cuando el agente ha tomado veinte decisiones incorrectas en cadena.
¿Por dónde empiezo si nunca he trabajado de forma estructurada con agentes?
Empieza por el Plan y el Decompose. Son los dos pasos del agentic engineering que más impacto tienen en la calidad del output y los que más developers saltan. Coge una tarea concreta de tu backlog y antes de lanzar el agente escribe: objetivo específico, contexto relevante y criterios de éxito. Luego divídela en subtareas que tengan bordes claros. Esas dos prácticas solas van a mejorar notablemente la calidad de lo que obtienes. El resto del framework puedes añadirlo gradualmente.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.