ANTHROPIC_API_KEY=sk-ant-xxxxxxxx
---
## Paso 1: El servidor backend con streamText
Crea un archivo `server/chat.ts` fuera del proyecto Angular (o en un monorepo aparte). Este servidor tiene un solo endpoint: recibe mensajes, llama a Claude, y hace streaming de la respuesta.
```typescript
// server/chat.ts
import { streamText } from 'ai';
import { anthropic } from '@ai-sdk/anthropic';
const server = Bun.serve({
port: 3000,
async fetch(req) {
// CORS para desarrollo local
if (req.method === 'OPTIONS') {
return new Response(null, {
headers: {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST, OPTIONS',
'Access-Control-Allow-Headers': 'Content-Type',
},
});
}
if (req.method === 'POST' && new URL(req.url).pathname === '/api/chat') {
const { messages } = await req.json();
const result = streamText({
model: anthropic('claude-sonnet-4-6'),
system: 'Eres un asistente técnico especializado en Angular y desarrollo frontend moderno. Responde en español de forma concisa y directa.',
messages,
});
return result.toTextStreamResponse({
headers: {
'Access-Control-Allow-Origin': '*',
},
});
}
return new Response('Not found', { status: 404 });
},
});
console.log(`Servidor corriendo en http://localhost:${server.port}`);
Arrancar el servidor:
bun run server/chat.ts
streamText de la AI SDK devuelve un objeto con varios métodos. toTextStreamResponse() genera una Response HTTP estándar con Content-Type: text/plain; charset=utf-8 y Transfer-Encoding: chunked — exactamente lo que necesita el cliente para consumir el stream token a token.
Paso 2: El modelo de datos
Antes del componente, define la interfaz de mensaje. Simple:
// src/app/chat/chat.types.ts
export interface ChatMessage {
role: 'user' | 'assistant';
content: string;
}
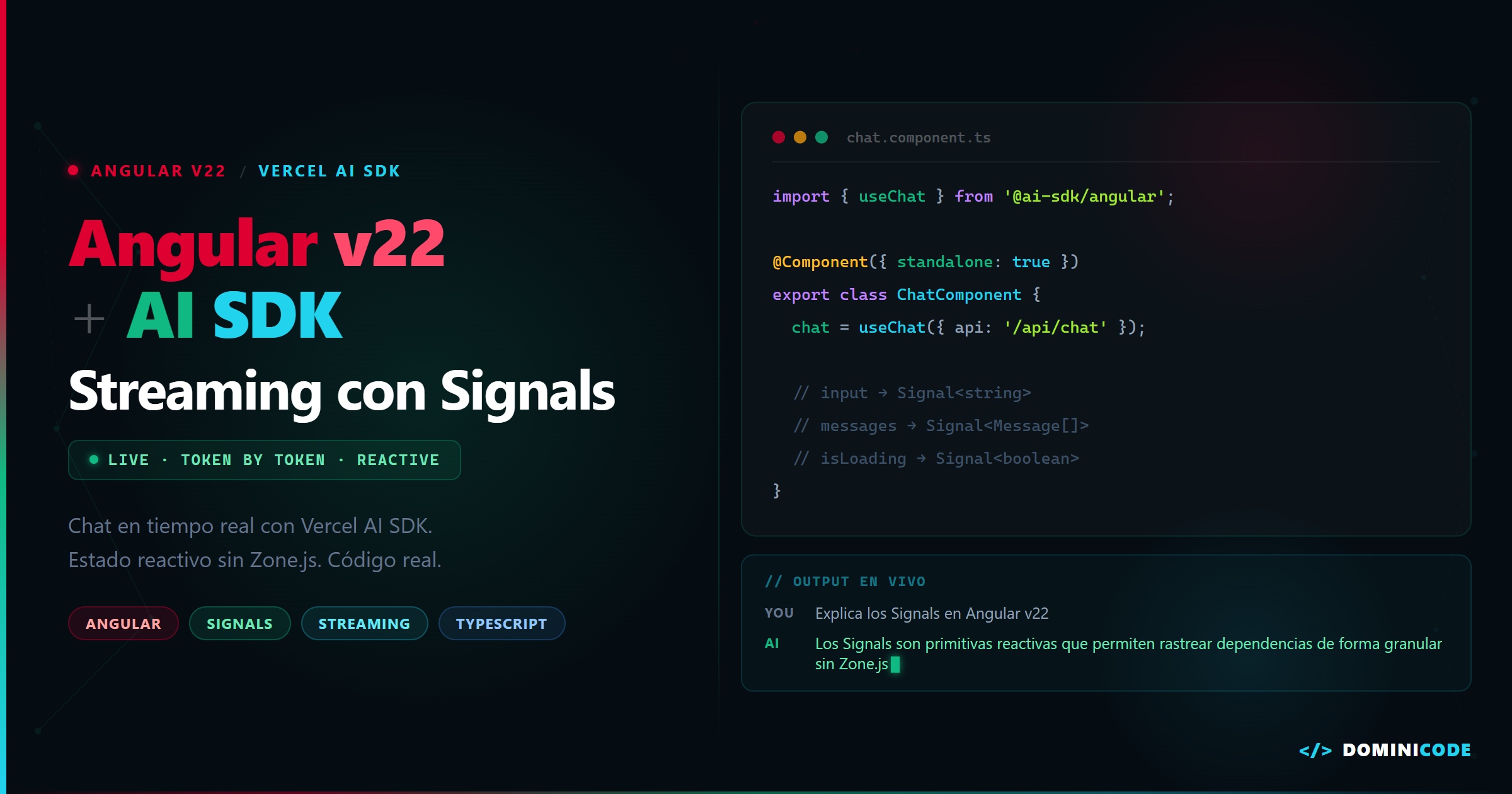
Paso 3: El componente Angular v22 con Signals
Aquí es donde la magia ocurre. No necesitas HttpClient con responseType: 'text' — eso no soporta streaming incremental. Necesitas fetch nativo con ReadableStream.
// src/app/chat/chat.component.ts
import {
Component,
signal,
computed,
ChangeDetectionStrategy,
} from '@angular/core';
import { FormsModule } from '@angular/forms';
import { ChatMessage } from './chat.types';
@Component({
selector: 'app-chat',
standalone: true,
imports: [FormsModule],
changeDetection: ChangeDetectionStrategy.OnPush,
templateUrl: './chat.component.html',
})
export class ChatComponent {
messages = signal<ChatMessage[]>([]);
userInput = signal('');
isStreaming = signal(false);
canSend = computed(
() => this.userInput().trim().length > 0 && !this.isStreaming()
);
async sendMessage() {
const content = this.userInput().trim();
if (!content || this.isStreaming()) return;
// Añadir mensaje del usuario
this.messages.update((msgs) => [
...msgs,
{ role: 'user', content },
]);
this.userInput.set('');
this.isStreaming.set(true);
// Capturar mensajes ANTES del placeholder — la API rechaza content vacío como último mensaje
const messagesToSend = this.messages();
// Placeholder para la respuesta del asistente
this.messages.update((msgs) => [
...msgs,
{ role: 'assistant', content: '' },
]);
try {
const response = await fetch('http://localhost:3000/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ messages: messagesToSend }),
});
if (!response.ok) throw new Error(`HTTP ${response.status}`);
if (!response.body) throw new Error('No stream body');
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
// Actualiza el último mensaje (el del asistente) acumulando el chunk
this.messages.update((msgs) => {
const updated = [...msgs];
const last = updated[updated.length - 1];
updated[updated.length - 1] = {
...last,
content: last.content + chunk,
};
return updated;
});
}
} catch (error) {
console.error('Error en streaming:', error);
this.messages.update((msgs) => {
const updated = [...msgs];
updated[updated.length - 1] = {
role: 'assistant',
content: 'Error al conectar con el servidor. Comprueba que el backend está corriendo.',
};
return updated;
});
} finally {
this.isStreaming.set(false);
}
}
handleEnter(event: KeyboardEvent) {
if (event.key === 'Enter' && !event.shiftKey) {
event.preventDefault();
this.sendMessage();
}
}
}
Tres decisiones clave en este componente:
messages = signal<ChatMessage[]>([]) — todo el historial de la conversación vive en un signal. Cada vez que llega un chunk, actualizamos el último mensaje del array con update(). Angular detecta el cambio y re-renderiza solo ese elemento.
ChangeDetectionStrategy.OnPush — esencial para este patrón. Sin esto, Angular ejecutaría la detección de cambios en cada tick mientras el stream está activo. Con OnPush + Signals, Angular solo actualiza cuando el signal cambia — que es exactamente cuando llega un chunk nuevo.
fetch nativo en lugar de HttpClient — HttpClient es poderoso para peticiones normales, pero para streaming necesitas acceso al ReadableStream crudo del Response. fetch te da eso directamente con response.body.getReader().
Paso 4: El template con el nuevo control flow
El template aprovecha el control flow de Angular v17+ (@for, @if) y lee los signals directamente — sin async pipe, sin | async, sin subscripciones.
<!-- src/app/chat/chat.component.html -->
<div class="chat-container">
<div class="messages-area">
@if (messages().length === 0) {
<p class="empty-state">Escribe un mensaje para empezar.</p>
}
@for (msg of messages(); track $index) {
<div class="message" [class]="msg.role">
<span class="role-label">
{{ msg.role === 'user' ? 'Tú' : 'Asistente' }}
</span>
<p class="message-content">{{ msg.content }}</p>
@if (msg.role === 'assistant' && $last && isStreaming()) {
<span class="cursor-blink">|</span>
}
</div>
}
</div>
<div class="input-area">
<textarea
[value]="userInput()"
(input)="userInput.set($any($event.target).value)"
(keydown)="handleEnter($event)"
placeholder="Escribe tu mensaje... (Enter para enviar)"
rows="3"
[disabled]="isStreaming()"
></textarea>
<button
(click)="sendMessage()"
[disabled]="!canSend()"
>
@if (isStreaming()) {
Generando...
} @else {
Enviar
}
</button>
</div>
</div>
El cursor parpadeante | aparece solo en el último mensaje del asistente mientras isStreaming() es true. Es un detalle pequeño que hace que la experiencia se sienta viva.
Paso 5: Estilos mínimos (opcional)
/* src/app/chat/chat.component.css */
.chat-container {
display: flex;
flex-direction: column;
height: 100vh;
max-width: 800px;
margin: 0 auto;
padding: 1rem;
gap: 1rem;
}
.messages-area {
flex: 1;
overflow-y: auto;
display: flex;
flex-direction: column;
gap: 1rem;
padding: 1rem;
border: 1px solid #e5e7eb;
border-radius: 0.5rem;
}
.message {
padding: 0.75rem 1rem;
border-radius: 0.5rem;
max-width: 80%;
}
.message.user {
background: #e90464;
color: white;
align-self: flex-end;
}
.message.assistant {
background: #f3f4f6;
color: #111827;
align-self: flex-start;
}
.role-label {
font-size: 0.75rem;
font-weight: 600;
opacity: 0.7;
display: block;
margin-bottom: 0.25rem;
}
.cursor-blink {
animation: blink 1s step-end infinite;
}
@keyframes blink {
50% { opacity: 0; }
}
.input-area {
display: flex;
gap: 0.5rem;
}
textarea {
flex: 1;
padding: 0.75rem;
border: 1px solid #d1d5db;
border-radius: 0.5rem;
resize: none;
font-family: inherit;
}
button {
padding: 0.75rem 1.5rem;
background: #e90464;
color: white;
border: none;
border-radius: 0.5rem;
cursor: pointer;
font-weight: 600;
align-self: flex-end;
}
button:disabled {
opacity: 0.5;
cursor: not-allowed;
}
El resultado
Arranca los dos procesos:
# Terminal 1: backend
bun run server/chat.ts
# Terminal 2: Angular
ng serve
Abre http://localhost:4200. Escribe cualquier pregunta técnica. Las palabras aparecen token a token mientras Claude las genera. El botón muestra "Generando…" y el cursor parpadea al final del último mensaje.
Eso es streaming real, en Angular v22, con Signals, en menos de 20 minutos.
Por qué este patrón funciona bien en producción
Si quieres entender cómo se conectan estos patrones con el desarrollo de productos completos con IA, el post sobre cómo crear productos con IA para vender muestra el panorama completo.
Lo que tienes aquí no es un prototipo. Es un patrón que escala:
El estado es predecible. Todo vive en messages = signal<ChatMessage[]>([]). No hay subscripciones dispersas, no hay Subject de BehaviorSubject, no hay que recordar hacer unsubscribe. El signal se actualiza, Angular re-renderiza lo necesario, punto.
El backend es stateless. Cada petición envía el historial completo de mensajes. Así funciona la API de Anthropic — no hay sesión en el servidor, lo que facilita el escalado horizontal.
ChangeDetectionStrategy.OnPush es obligatorio aquí. Con Zone.js y la detección de cambios por defecto, Angular correría su ciclo de detección constantemente mientras el stream está activo. Con OnPush + Signals, solo actualiza cuando el signal cambia.
Si quieres llevar esto más allá — añadir herramientas (tool calls), mantener sesiones con localStorage, o integrar el chat dentro de una app Angular más grande con routing y autenticación — el patrón es el mismo. Cambias el modelo en el servidor, añades tools a streamText, y el componente no necesita modificarse.
Si ya tienes experiencia con Angular y quieres dominar Signals, componentes standalone y el control flow moderno que hemos usado aquí, en el Curso Angular Moderno lo cubrimos desde la arquitectura hasta producción — incluyendo patrones de integración con APIs externas como esta.
Y si quieres ir más allá del chat básico y construir agentes reales con Claude — con herramientas, contexto persistente, y pipelines de desarrollo AI-first — eso es exactamente lo que enseñamos en Construye con IA: de la idea al producto con Claude Code.
FAQ
¿Necesito Angular Universal (SSR) para que esto funcione?
No. El streaming ocurre entre el cliente Angular (browser) y el servidor Bun que creamos. Angular SSR es irrelevante para este patrón — el componente de chat vive completamente en el cliente. Si tienes SSR activado, asegúrate de que el componente de chat solo se renderiza en el browser con isPlatformBrowser o usando @defer.
¿Puedo usar el mismo enfoque con OpenAI o Google Gemini en lugar de Anthropic?
Sí. Cambia @ai-sdk/anthropic por @ai-sdk/openai o @ai-sdk/google, y sustituye anthropic('claude-sonnet-4-6') por openai('gpt-4o') o google('gemini-2.5-pro'). El resto del código — el componente Angular, el consumo del stream, los Signals — no cambia. Esa es una de las ventajas del Vercel AI SDK: abstrae el proveedor.
¿Qué pasa si el usuario envía el siguiente mensaje mientras el anterior aún está en streaming?
El botón está deshabilitado mientras isStreaming() es true gracias al computed canSend. El usuario no puede enviar otro mensaje hasta que el stream termine. Si quieres cancelar el stream activo al recibir un nuevo mensaje, puedes guardar el reader como propiedad del componente y llamar a reader.cancel() antes de iniciar la nueva petición.
¿Cómo manejo el historial para conversaciones largas?
La API de Anthropic tiene un límite de tokens por request. Para conversaciones largas, lo más simple es limitar el historial que envías al servidor — por ejemplo, los últimos 20 mensajes. En producción, lo correcto es implementar una ventana deslizante o resumir el historial antiguo con un llamada previa al modelo. Por ahora, con this.messages().slice(-20) en el body del fetch tienes un control básico suficiente para empezar.
¿Puedo usar HttpClient en lugar de fetch nativo?
HttpClient con responseType: 'text' recibe el texto completo cuando la conexión cierra — no es streaming incremental. Para streaming real necesitas acceso al ReadableStream crudo de la Response, que solo fetch te proporciona directamente. Podrías implementar un interceptor custom o un HttpBackend alternativo, pero la complejidad no vale la pena. fetch nativo es la solución correcta aquí.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.