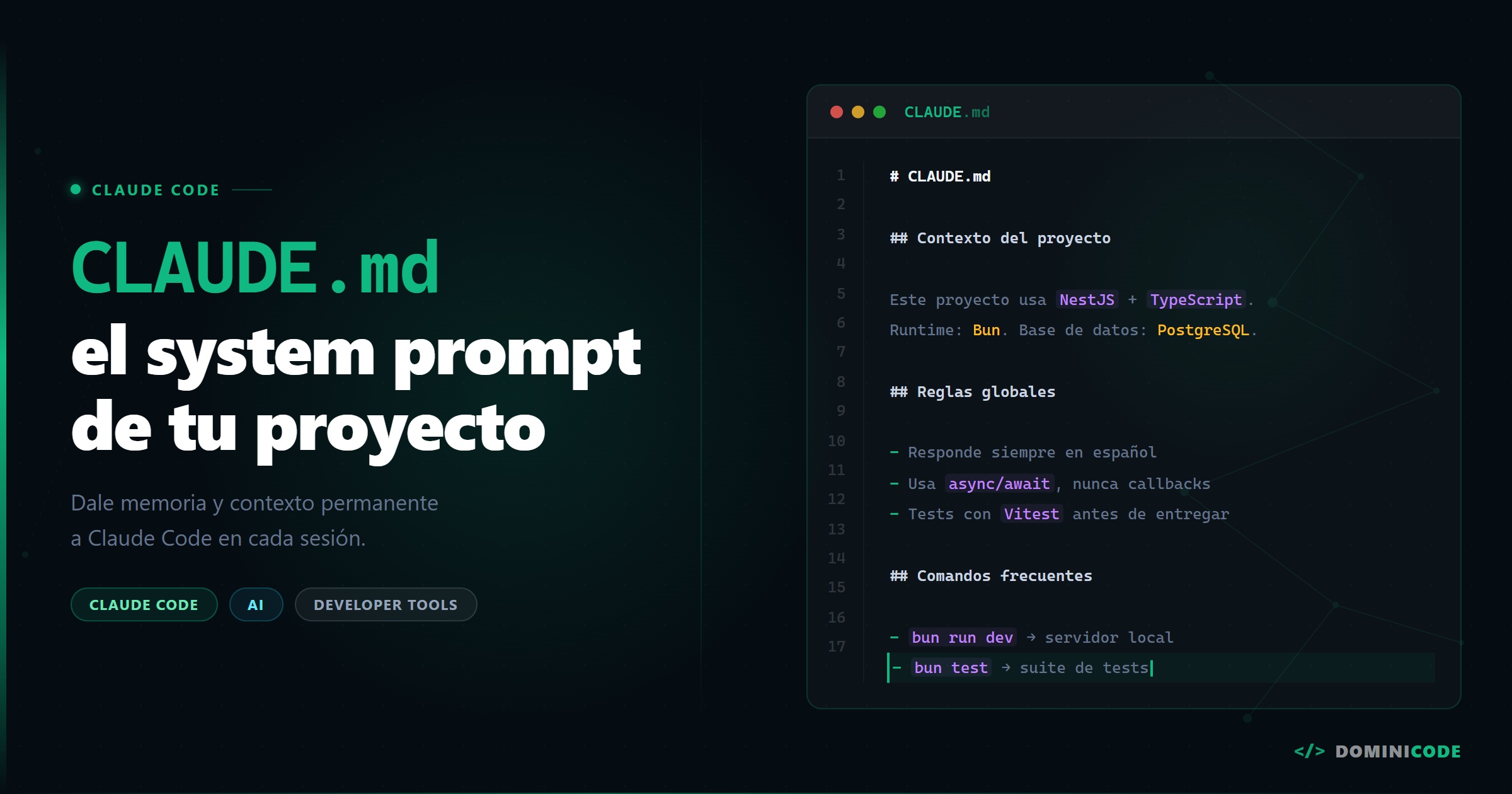
El problema no es que falten herramientas para construir agentes de IA. Es que sobran.
Hace unos meses, en una sesión de Dominicode Labs, me preguntaron cuál era el stack IA agéntica 2026 que recomendaba. Empecé a responder y me di cuenta de que tenía una respuesta para cada capa — pero no tenía una respuesta integrada. Llevo varios proyectos agénticos en producción en Dominicode y cada semana aparece un nuevo framework, un nuevo modelo, un nuevo “estándar imprescindible”.
Qué modelo. Qué framework de orquestación. Qué hacer con la memoria. Cómo trazar lo que hace el agente. Dónde desplegarlo. Cada capa tiene sus propias opciones, sus propias compensaciones y su propio ecosistema de hype que no para de generar nuevas herramientas.
Este post es mi respuesta integrada: el stack que yo uso, por qué elegí cada pieza y qué descarto con criterio. No es una lista de todas las herramientas que existen. Es una guía con tesis clara sobre qué funciona en producción cuando construyes con TypeScript, para un proyecto real, sin un equipo de 20 personas.
Cómo pensar en el stack agéntico: capas, no herramientas
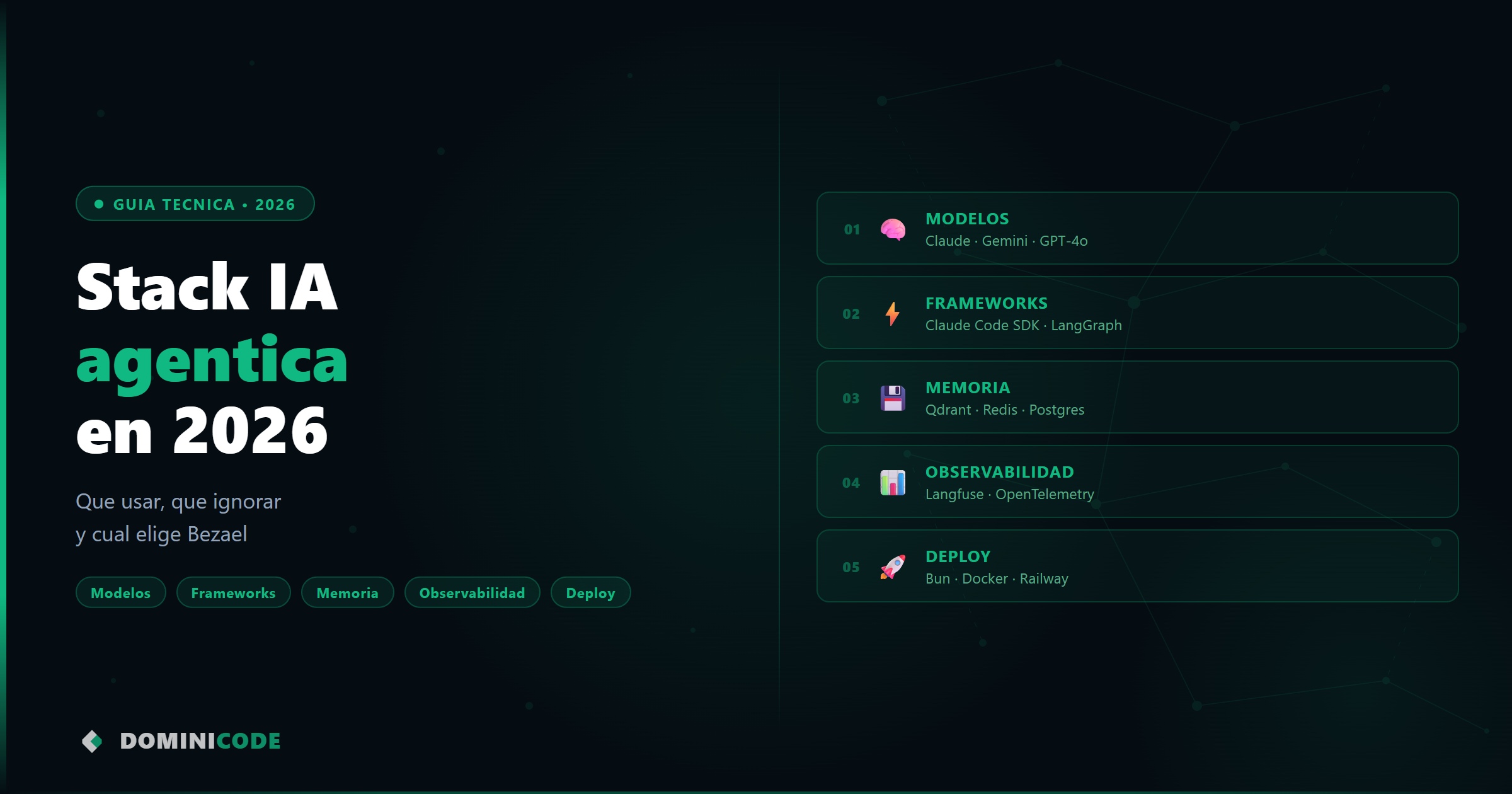
Antes de hablar de herramientas específicas, el marco que uso para evaluar cualquier stack agéntico. Hay cinco capas y cada una resuelve un problema diferente:
- Modelo — el LLM que razona y toma decisiones
- Framework de agente — el runtime que envuelve el agentic loop
- Memoria y contexto — dónde vive la información entre sesiones y entre agentes
- Observabilidad — cómo ves qué está haciendo el agente
- Deployment — dónde corre el sistema en producción
La mayoría de los posts sobre herramientas de IA mezclan estas capas y crean confusión. LangChain no compite con Claude — compite con el SDK de Anthropic. Langfuse no compite con Pinecone — resuelven problemas en capas completamente distintas.
Cuando tienes claro qué capa resuelve cada herramienta, la decisión se vuelve mucho más simple. Si no tienes claro aún qué es el agentic loop y cómo funciona, empieza por aquí antes de elegir el stack.
Capa 1: El modelo — quién razona
La decisión más importante del stack y la que más gente toma al revés: eligen el modelo por el benchmark, no por el comportamiento en producción con herramientas.
Los benchmarks de razonamiento abstracto no predicen bien si un modelo va a gestionar correctamente el agentic loop: respetar los límites de las herramientas, detectar cuándo ha completado el objetivo, no inventarse argumentos para las tool calls, pedir confirmación cuando tiene ambigüedad.
Mi ranking para sistemas agénticos en 2026, basado en uso real:
Claude Sonnet (Anthropic) — mi elección principal. La familia Claude 4.x lidera en comportamiento agéntico: sigue instrucciones complejas del sistema prompt con más fidelidad que los competidores, gestiona bien contextos de 200k tokens, y tiene el menor índice de “tool hallucination” — inventarse argumentos para herramientas que no existen o llamar a herramientas con parámetros incorrectos. Para proyectos donde el agente tiene acceso a herramientas reales con consecuencias (escritura a disco, llamadas a APIs, base de datos), esta fidelidad importa.
Gemini 2.5 Pro (Google) — segunda opción para tareas de análisis. Tiene una ventana de contexto de 1M tokens que es genuinamente útil cuando el agente necesita procesar documentos grandes. El razonamiento es sólido. La API tiene más latencia que Anthropic en llamadas con herramientas. Lo uso puntualmente para tareas de análisis de documentos extensos, no como backbone de un sistema agéntico.
GPT-4o (OpenAI) — bueno, pero no es mi primera elección para agentes. Excelente en tareas de generación pura. En agentic loops de más de 15 iteraciones, he visto más context drift que con Claude. Para proyectos que ya tienen infraestructura en el ecosistema OpenAI, es perfectamente válido.
Llama 3.x local (Meta) — para casos específicos, no como base. Los modelos locales tienen su lugar: privacidad total, sin costos por token, sin latencia de red. Pero para sistemas agénticos complejos, la diferencia en calidad de razonamiento con los modelos de frontera es demasiado grande hoy. Los uso para tareas de clasificación simple o cuando los datos no pueden salir del entorno.
La conclusión práctica: empieza con Claude Sonnet. Si los costos escalan y la tarea lo permite, evalúa migrar partes del sistema a modelos más baratos para subtareas que no requieren razonamiento complejo.
Capa 2: El framework de agente — quién orquesta el loop
Aquí está la decisión que más polémica genera, porque hay muchas opciones y cada una tiene su comunidad apasionada.
Mi posición es clara: el framework que elijas debería desaparecer de tu código. Si tu lógica de negocio está mezclada con abstracciones del framework, tienes un problema de arquitectura, no de elección de herramienta.
Vercel AI SDK — mi elección para TypeScript
Para proyectos TypeScript, el Vercel AI SDK es el estándar más sólido hoy. Tiene tres propiedades que importan:
Primero, la abstracción es mínima. generateText, streamText, generateObject — funciones que hacen lo que dicen, con un tipo de retorno predecible. Puedes leer el código del SDK y entender qué ocurre.
Segundo, es agnóstico al proveedor. El mismo código funciona con Claude, GPT-4o y Gemini. Cambias el adaptador, no la lógica. En un año donde los modelos evolucionan rápido, esto no es un detalle menor.
Tercero, tiene soporte nativo para tool use, streaming de respuestas y generateObject con schemas Zod — lo que significa que puedes hacer que el modelo devuelva JSON tipado sin analizadores de texto frágiles.
import { generateText } from "ai";
import { anthropic } from "@ai-sdk/anthropic";
import { z } from "zod";
const result = await generateText({ model: anthropic("claude-sonnet-4-6"), // verifica el modelo vigente en docs.anthropic.com/models tools: { readFile: { description: "Lee el contenido de un archivo del proyecto", parameters: z.object({ path: z.string() }), execute: async ({ path }) => fs.readFile(path, "utf-8"), }, }, messages: [{ role: "user", content: userQuery }], maxSteps: 15, // límite de iteraciones del loop });
El parámetro maxSteps es el límite de iteraciones del agentic loop. No lo omitas nunca. Un agente sin límite de pasos en producción es un bug esperando a ocurrir.
LangGraph — cuando necesitas flujos con estado y ramificaciones
LangGraph (de LangChain) resuelve un problema diferente: orquestación de flujos donde el camino de ejecución no es lineal. Si tienes un sistema donde el agente puede ir por diferentes ramas según el resultado de un paso anterior, donde necesitas estado persistente entre sesiones, o donde hay handoffs entre múltiples agentes con condiciones complejas — LangGraph tiene primitivas para eso.
No es mi primera elección para proyectos simples porque añade complejidad conceptual. Pero para sistemas multi-agente con lógica de routing elaborada, es genuinamente más potente que construir esa lógica a mano.
SDK de Anthropic directo — para control total
Cuando necesito control máximo sobre cada llamada a la API, uso el SDK de Anthropic directamente. Sin abstracciones intermedias. El agentic loop lo implemento yo, con la lógica exacta que necesito.
Esto es lo que haría si estuviera construyendo el loop desde cero con el SDK directo — el mismo patrón que cubro en detalle en el curso Construye con IA:
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
async function runAgentLoop(userMessage: string, tools: Tool[]) { const messages: Anthropic.MessageParam[] = [ { role: "user", content: userMessage }, ];
let iterations = 0; const maxIterations = 20;
while (iterations < maxIterations) { const response = await client.messages.create({ model: "claude-sonnet-4-6", // verifica en docs.anthropic.com/models max_tokens: 4096, tools, messages, });
// Si el modelo no llama a ninguna herramienta, ha terminado if (response.stop_reason === "end_turn") { return extractTextResponse(response); }
// Procesa las tool calls y añade los resultados al contexto const toolResults = await executeToolCalls(response.content); messages.push({ role: "assistant", content: response.content }); messages.push({ role: "user", content: toolResults });
iterations++; }
throw new Error(Agente excedió el límite de ${maxIterations} iteraciones); }
Lo que no uso: CrewAI, AutoGen, AgentGPT ni la mayoría de frameworks Python-first para proyectos TypeScript. No porque sean malos — CrewAI tiene ideas interesantes sobre roles y colaboración entre agentes — sino porque añadir Python al stack cuando ya tienes TypeScript es complejidad operacional que no se justifica en la mayoría de casos. Si tu equipo es Python, la ecuación cambia.
Capa 3: MCP — el protocolo que está cambiando todo
El Model Context Protocol (MCP) merece su propio apartado porque no es un framework de agentes. Es un estándar de comunicación — el equivalente a REST para que los agentes consuman herramientas y contexto de fuentes externas de forma estandarizada.
Antes de MCP, cada herramienta que querías darle a un agente requería código de integración específico. Con MCP, una herramienta bien construida se puede conectar a cualquier agente que soporte el protocolo — Claude Code, Cursor, tu propio agente custom.
Las implicaciones son grandes: en lugar de construir integraciones punto a punto, construyes servidores MCP reutilizables. Ya existe un ecosistema de servidores MCP públicos para GitHub, bases de datos, sistemas de archivos, APIs populares.
// Un servidor MCP mínimo con el SDK oficial
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { ListToolsRequestSchema } from "@modelcontextprotocol/sdk/types.js";
const server = new Server( { name: "dominicode-tools", version: "1.0.0" }, { capabilities: { tools: {} } } );
server.setRequestHandler(ListToolsRequestSchema, async () => ({ tools: [ { name: "get_post_metrics", description: "Obtiene métricas de un post del blog por slug", inputSchema: { type: "object", properties: { slug: { type: "string" } }, required: ["slug"], }, }, ], }));
const transport = new StdioServerTransport(); await server.connect(transport);
En 2026, si construyes herramientas para agentes y no las expones como servidores MCP, estás construyendo para un solo cliente. El ecosistema ya se está moviendo en esta dirección — Anthropic, OpenAI, Google y la mayoría de los frameworks de agentes tienen soporte nativo para MCP.
Capa 4: Memoria y contexto persistente
El problema de la memoria en agentes agénticos tiene tres dimensiones distintas y cada una necesita una solución diferente.
Memoria conversacional (corto plazo) — el historial de mensajes de la sesión actual. La gestión correcta es mantenerlo en el contexto de la llamada al LLM. El truco está en la truncación inteligente: cuando el contexto se acerca al límite, no cortes los mensajes más antiguos a ciegas — resume las iteraciones antiguas y mantén los más recientes completos.
Memoria semántica (búsqueda por similaridad) — para cuando el agente necesita recuperar información relevante de una base de conocimiento grande. Las opciones que uso:
- pgvector — extensión de PostgreSQL. Si ya tienes Postgres en el stack (y probablemente lo tienes), añadir pgvector es añadir una extensión. No necesitas otra base de datos. Para la mayoría de proyectos con menos de diez millones de embeddings, pgvector es suficiente y elimina complejidad operacional.
- Pinecone — la opción gestionada cuando el volumen es grande o quieres zero-ops. Más caro, más simple. Para proyectos en fases tempranas con presupuesto ajustado, pgvector primero.
- Supabase pgvector — pgvector sobre Supabase. La que uso en proyectos nuevos porque ya tengo Supabase en el stack para auth y database.
Memoria episódica (estado entre sesiones) — lo que el agente recuerda de sesiones anteriores con un usuario específico. Esto no es búsqueda vectorial: es estado estructurado que guardas en una tabla normal. El patrón que funciona es guardar un JSON con los hechos relevantes del usuario o proyecto y cargarlo al inicio de cada sesión como parte del system prompt.
// Carga el estado de memoria al inicio de la sesión
async function buildSystemPromptWithMemory(userId: string): Promise<string> {
const memory = await db.query<UserMemory>(
"SELECT facts FROM agent_memory WHERE user_id = $1",
[userId]
);
const memoryContext = memory.rows[0]?.facts ? \n\nContexto previo del usuario:\n${JSON.stringify(memory.rows[0].facts, null, 2)} : "";
return Eres un asistente técnico de Dominicode.${memoryContext}; }
Capa 5: Observabilidad — ver lo que hace el agente
Sin observabilidad, un agente en producción es una caja negra que factura. Ya hay un post completo en este blog sobre cómo instrumentar tus agentes con Langfuse y OpenTelemetry, así que aquí voy directo a las decisiones de stack:
Langfuse — la elección por defecto. Open source, autohospedable, SDK para TypeScript con integración nativa en el Vercel AI SDK. Con un experimental_telemetry en la llamada tienes trazas completas:
const result = await generateText({
model: anthropic("claude-sonnet-4-6"), // verifica el modelo vigente en docs.anthropic.com/models
messages,
tools,
experimental_telemetry: { // en Vercel AI SDK v4+ puede ser telemetry sin el prefijo
isEnabled: true,
metadata: { userId, sessionId, operationType: "support-agent" },
},
});OpenTelemetry GenAI — si ya tienes infraestructura OTEL en la empresa, las semantic conventions para IA generativa te permiten integrar las trazas de tus agentes en Grafana, Datadog o Honeycomb sin añadir otra plataforma.
Helicone — proxy sin código si necesitas observabilidad inmediata sin instrumentar. Un cambio de base URL y tienes dashboards. Útil para proyectos donde no puedes tocar el código de integración.
Capa 6: Deployment — dónde vive el agente en producción
Las opciones razonables en 2026, con criterio claro sobre cuándo usar cada una:
Railway — mi primera opción para agentes con estado o procesos de larga duración. Soporta WebSockets, procesos persistentes y tiene buena DX con Docker. Para agentes que necesitan mantener conexiones abiertas o procesar en background, Railway es más natural que Vercel.
Vercel — ideal para agentes stateless que responden a webhooks o peticiones HTTP. La integración con el Vercel AI SDK es perfecta — maxDuration hasta 300 segundos en planes Pro es suficiente para la mayoría de las respuestas agénticas. Para workflows que duran minutos, necesitas otra opción.
Cloudflare Workers + Durable Objects — la opción de mayor rendimiento para agentes edge. Durable Objects resuelve el problema de estado en entornos serverless de forma elegante. La curva de aprendizaje es mayor, pero el resultado en latencia y coste a escala es difícil de igualar.
Docker + VPS — cuando necesitas control total, costos predecibles a escala media y no quieres depender de plataformas específicas. Es lo que uso para los agentes internos de Dominicode que corren de forma continua.
Una regla práctica: si el agente responde en menos de 30 segundos y no necesita estado entre llamadas, serverless es suficiente. Si el agente trabaja durante minutos, mantiene conexiones o necesita acceso a recursos locales, necesitas un proceso persistente.
Mi stack en Dominicode: la versión concreta
Sin rodeos. Esto es exactamente lo que uso:
| Capa | Herramienta | Por qué |
|---|---|---|
| Modelo principal | Claude Sonnet (Anthropic) | Mejor comportamiento en agentic loops, 200k contexto |
| Modelo para análisis | Gemini 2.5 Pro | Contexto 1M para documentos grandes |
| Runtime | Bun | Arranque más rápido, compatibilidad TS nativa, fetch nativo |
| Framework de agente | Vercel AI SDK | Tipado TS sólido, agnóstico al proveedor, maxSteps nativo |
| Herramientas custom | MCP servers propios | Reutilizables entre agentes, estándar abierto |
| Memoria semántica | Supabase + pgvector | Postgres ya en el stack, zero overhead operacional |
| Memoria episódica | Postgres (tabla JSON) | No necesita búsqueda vectorial, estado estructurado |
| Observabilidad | Langfuse cloud | Open source, free tier generoso, integración VAISDK |
| Deployment (agentes web) | Vercel | Integración natural con el SDK |
| Deployment (procesos) | Railway + Docker | Agentes de larga duración, procesos internos |
| Validación | Zod | Schemas para tool inputs y outputs tipados |
La parte que más me preguntan es el runtime: por qué Bun y no Node. La respuesta corta: en scripts de agentes que arrancan y terminan frecuentemente, la diferencia de arranque es perceptible. El soporte nativo de TypeScript elimina el paso de transpilación en scripts de herramientas. Y fetch nativo sin polyfills simplifica el código de integración con APIs externas.
Lo que descarto y por qué
LangChain (la librería base) — demasiada abstracción sobre abstracciones. El problema no es que sea mala herramienta: es que cuando algo falla en un agente LangChain, la pila de herencia de clases hace que depurar sea más difícil que si hubieras implementado el loop a mano. LangGraph tiene más sentido para flujos complejos, pero la librería base la evito.
AutoGen (Microsoft) — interesante para investigación, inconsistente en producción. El modelo de conversación entre agentes es elegante en teoría, pero en proyectos reales he visto bucles de conversación que consumen tokens sin converger. Puede mejorar, pero hoy no lo usaría para un sistema que atiende usuarios reales.
Pinecone como primera opción — no porque sea malo, sino porque pgvector en Postgres elimina una dependencia externa para la mayoría de los casos de uso. Cuando el volumen de embeddings supere los diez millones o necesites búsquedas en milisegundos a escala muy alta, Pinecone tiene sentido. Antes, no.
Modelos locales como backbone — la brecha de calidad con los modelos de frontera es demasiado grande para sistemas agénticos complejos. Para clasificación de intenciones sencillas o filtros de moderación, tiene sentido. Para el loop principal de un agente que toma decisiones consecuentes, no lo haría hoy.
El stack no es el problema
La decisión de stack importa — pero menos de lo que sugiere el volumen de contenido que se publica sobre herramientas de IA cada semana.
He visto proyectos con el stack perfecto que fallaban en producción por falta de observabilidad. He visto proyectos con stacks “incorrectos” que funcionaban perfectamente porque el equipo entendía qué estaba haciendo.
El stack es el entorno. Lo que importa es entender cómo funciona el agentic loop, cómo diseñar herramientas que el modelo pueda usar de forma predecible, y cómo instrumentar el sistema para ver qué ocurre cuando algo falla.
Si quieres construir esto desde cero con criterio — desde el primer loop hasta el sistema completo en producción — en el curso Construye con IA cubrimos exactamente estas decisiones: qué stack elegir para cada tipo de proyecto, cómo estructurar el código para que sea mantenible, y cómo pasar de prototipo a sistema que funciona cuando no estás mirando.
Y si quieres el marco metodológico para especificar el sistema antes de escribir una línea de código — evitar construir el agente equivocado — el libro de Spec-Driven Development es la guía que yo sigo antes de abrir el editor.
FAQ — Preguntas frecuentes sobre el stack de IA agéntica
¿Qué framework de agentes es mejor en 2026: Vercel AI SDK, LangGraph o el SDK directo de Anthropic?
Depende de la complejidad del sistema. Para la mayoría de proyectos TypeScript con flujos lineales, el Vercel AI SDK ofrece el mejor equilibrio entre abstracción mínima y productividad: tipado sólido, soporte nativo para tool use y streaming, y compatibilidad con múltiples proveedores. LangGraph añade valor cuando el flujo tiene ramificaciones complejas, estado persistente entre pasos o múltiples agentes con routing condicional. El SDK directo de Anthropic tiene sentido cuando necesitas control total sobre cada llamada o cuando las abstracciones intermedias ocultan comportamiento que necesitas ver.
¿Necesito una base de datos vectorial para construir un agente?
No necesariamente. La memoria vectorial solo es necesaria cuando el agente necesita recuperar información relevante de un corpus grande de documentos. Si el agente trabaja con un contexto fijo que cabe en la ventana de contexto del modelo (y con 200k tokens de Claude, cabe mucho), no necesitas embeddings ni búsqueda vectorial. Cuando el corpus supera lo que cabe en contexto, empieza por pgvector en Postgres antes de añadir Pinecone u otra base de datos vectorial externa.
¿Qué es MCP y por qué debería importarme en 2026?
El Model Context Protocol es un estándar abierto que define cómo los agentes de IA consumen herramientas y contexto de fuentes externas. Su importancia práctica: en lugar de construir integraciones específicas para cada agente que quieras conectar a una herramienta, construyes un servidor MCP una vez y cualquier agente compatible puede usarlo. Claude Code, Cursor y la mayoría de los IDEs con IA ya soportan MCP. Si construyes herramientas para agentes hoy, exponerlas como servidores MCP multiplica su utilidad sin trabajo adicional.
¿Puedo usar Python para construir el stack agéntico si ya soy developer Python?
Sí, y tiene sentido si Python es tu lenguaje principal. El ecosistema de agentes en Python es más maduro en algunos aspectos: LangChain, AutoGen, CrewAI y la mayoría de frameworks de referencia nacieron en Python. Lo que pierdes en TypeScript: algunas integraciones no tienen SDK Python equivalente al mismo nivel de calidad. Lo que ganas: ecosistema de ML más rico y más documentación de referencia. La decisión debe estar en el lenguaje que dominas, no en el que tiene más hype.
¿Cómo elijo entre Railway y Vercel para desplegar un agente?
La regla práctica: si el agente responde a peticiones HTTP en menos de 60 segundos y no necesita mantener estado entre llamadas, Vercel Functions es suficiente y más simple. Si el agente trabaja en procesos de larga duración (más de un minuto), necesita WebSockets, mantiene conexiones persistentes, o accede a recursos locales del servidor, Railway con un contenedor Docker es la opción correcta. Cloudflare Workers + Durable Objects es la tercera opción para máxima performance edge cuando el coste a escala importa.
¿Qué herramienta de observabilidad recomendarías empezar primero?
Langfuse. El plan gratuito en cloud cubre 50.000 observaciones al mes, la integración con el Vercel AI SDK es de una línea de código (el parámetro experimental_telemetry), y si en algún momento necesitas privacidad total de los datos, puedes autohospedarlo con Docker. Si ya tienes infraestructura OpenTelemetry en la empresa, las semantic conventions GenAI de OTEL te permiten integrar sin añadir otra plataforma.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.