Era domingo por la noche. Tenía que probar un flujo de extracción de datos con un LLM y el presupuesto del cliente para APIs era cero. Nada aprobado, nada disponible.
La solución: correr modelos IA en local. Instalé Ollama en diez minutos, bajé Llama 3 y terminé el prototipo antes de medianoche sin gastar un solo centavo en tokens.
Eso es lo que te da correr modelos en local: velocidad, independencia y control total sobre lo que entra y lo que sale del modelo. Y en 2026, con los modelos open source en el estado en que están, la calidad ya no es una excusa para no hacerlo.
Correr modelos IA en local significa ejecutar un Large Language Model directamente en tu hardware — sin enviar datos a APIs externas, sin coste por token y con latencia controlada. Herramientas como Ollama hacen que el proceso sea tan sencillo como instalar cualquier CLI.
Por qué correr modelos en local (y cuándo importa de verdad)
Hay cuatro razones concretas. Y van más allá del coste.
Privacidad. Si trabajas con datos sensibles — contratos, código propietario, información médica — mandar esos datos a una API externa es un riesgo legal y contractual. Con modelos IA en local, los datos nunca salen de tu máquina.
Latencia. Una llamada a GPT-4o tiene entre 300ms y 2 segundos de ida y vuelta dependiendo del tamaño del prompt. Un modelo local bien configurado en una máquina decente responde en milisegundos para tareas simples. Si construyes herramientas de developer experience o pipelines de CI con IA, esa diferencia importa.
Iteración sin coste. En fases de prototipado puedes hacer miles de llamadas al día para testear prompts, ajustar pipelines y explorar comportamientos del modelo. Con una API de pago, eso se acumula rápido. En local, es gratis.
Trabajo offline. Aviones, conexiones lentas, redes corporativas con proxies restrictivos. Un modelo local funciona siempre.
Las dos herramientas que necesitas conocer
Ollama — la opción de developer
Ollama es la herramienta que más uso y la que recomiendo si eres developer. Es una CLI + servidor HTTP que gestiona la descarga, configuración y ejecución de modelos como si fueran contenedores Docker.
Funciona en macOS, Linux y Windows. Tiene una API REST compatible con el formato de OpenAI, lo que significa que puedes usar clientes existentes con un cambio mínimo de URL. Y tiene una comunidad activa con más de 100 modelos disponibles en su registry.
Si sabes usar Docker, Ollama te va a resultar natural inmediatamente.
LM Studio — la opción visual
LM Studio es la alternativa para quienes prefieren una interfaz gráfica. Permite navegar, descargar y comparar modelos con un chat visual, ideal para exploración inicial o para compartir con equipos no técnicos.
También tiene un servidor local compatible con OpenAI. La diferencia clave: Ollama es mejor para integrar en código y scripts; LM Studio es mejor para explorar modelos de forma interactiva.
Para este post me centro en Ollama porque es donde vive el flujo de trabajo real de un developer.
Tutorial: instalar Ollama y correr tu primer modelo
1. Instalación
macOS:
brew install --cask ollamaLinux:
curl -fsSL https://ollama.com/install.sh | shWindows:
Descarga el instalador desde ollama.com/download y ejecútalo. Ollama se instala como servicio y arranca automáticamente.
Una vez instalado, verifica que funciona:
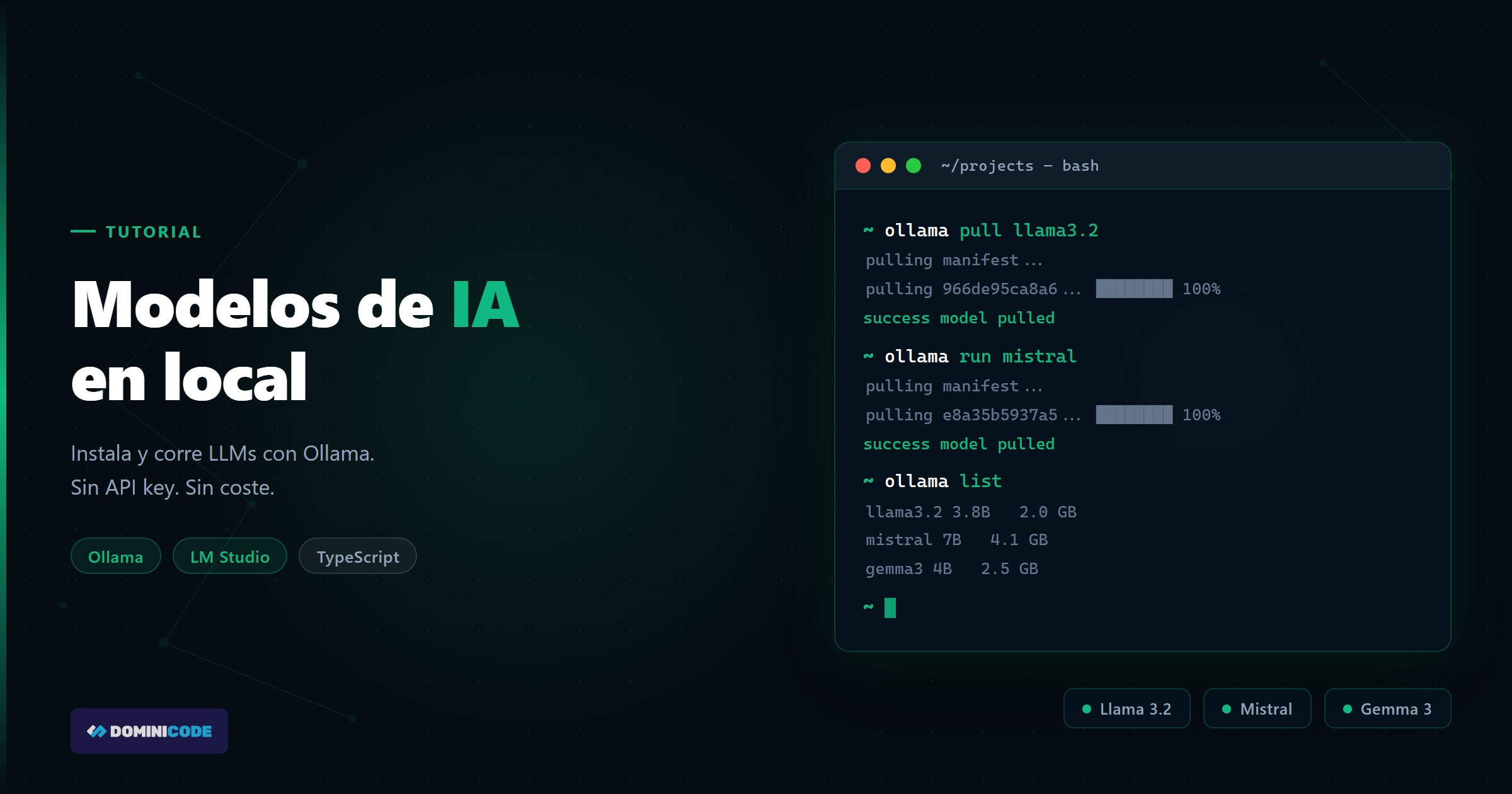
ollama --version2. Descargar y correr un modelo
# Descargar y correr Llama 3.2 (3B — ligero, ideal para empezar)
ollama run llama3.2
# Descargar sin abrir el chat
ollama pull llama3.2
# Descargar Mistral 7B
ollama pull mistral
# Descargar Gemma 3 (Google, muy eficiente)
ollama pull gemma3
# Descargar Qwen 2.5 (excelente en código)
ollama pull qwen2.5-coder
# Descargar Phi-4 (Microsoft, pequeño y capaz)
ollama pull phi4Al ejecutar ollama run se abre un REPL interactivo en la terminal. Escribe tu prompt y responde como cualquier chat. Para salir: /bye.
3. Gestionar modelos
# Ver modelos descargados
ollama list
# Eliminar un modelo
ollama rm mistral
# Ver información de un modelo
ollama show llama3.24. Usar la API REST de Ollama
Cuando Ollama está corriendo, expone una API en http://localhost:11434. Puedes usarla directamente con curl:
# Generar una respuesta (completions)
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"prompt": "Explica qué es un closure en JavaScript en dos frases",
"stream": false
}'
# Formato compatible con OpenAI (chat completions)
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "Qué es un closure en JavaScript?" }
]
}'El endpoint /v1/chat/completions es compatible con el SDK oficial de OpenAI. Solo tienes que cambiar la baseURL.
Modelos recomendados según caso de uso
Estos son los modelos IA en local con mejor rendimiento según el hardware disponible y el caso de uso:
| Modelo | Tamaño | Ideal para | RAM mínima |
|---|---|---|---|
llama3.2:3b |
~2 GB | Tareas simples, prototipado rápido | 8 GB |
llama3.1:8b |
~5 GB | Razonamiento general, chat | 8 GB |
mistral:7b |
~4 GB | Instrucciones, resumen, generación de texto | 8 GB |
qwen2.5-coder:7b |
~4 GB | Generación y revisión de código | 8 GB |
gemma3:9b |
~6 GB | Tareas multilingues, contexto largo | 16 GB |
phi4:14b |
~9 GB | Razonamiento complejo, análisis | 16 GB |
llama3.3:70b |
~40 GB | Calidad cercana a GPT-4o | 64 GB |
deepseek-r1:14b |
~9 GB | Razonamiento con chain-of-thought | 16 GB |
Para una máquina de desarrollo con 16 GB de RAM, qwen2.5-coder:7b para tareas de código y llama3.1:8b para texto general cubren el 90% de los casos.
Local vs nube: cuándo usar cada uno
| Criterio | Local (Ollama) | Nube (OpenAI, Anthropic, Google) |
|---|---|---|
| Coste por llamada | Gratis | $0.001–$0.015 por 1K tokens |
| Privacidad de datos | Total | Depende del proveedor y contrato |
| Calidad en tareas complejas | Buena (modelos 7B–14B) | Excelente (modelos frontier) |
| Latencia (primer token) | Baja en hardware potente | Varía: 300ms–2s |
| Escalabilidad | Limitada por tu hardware | Prácticamente ilimitada |
| Modelos de razonamiento avanzado | Limitado | o1, Claude Sonnet 4, Gemini 2.5 Pro |
| Setup inicial | 10 minutos | Registro + API key |
| Trabajo offline | Sí | No |
| Ideal para | Prototipado, privacidad, CI/CD, dev tooling | Producción con usuarios reales, tareas complejas |
La regla que uso: local para desarrollar, nube para producir. Prototipa barato, valida rápido, y cuando el producto necesita escalar o resolver tareas de mayor complejidad, mueve las llamadas críticas a un modelo cloud.
Integración con TypeScript y JavaScript
Ollama tiene su propio cliente oficial para Node.js. Dado que expone un endpoint compatible con OpenAI, puedes usar el paquete openai directamente — sin reescribir nada en tus proyectos existentes. Después de integrar modelos IA en local en varios proyectos TypeScript, estos son los tres patrones que más uso en producción:
Con el SDK de OpenAI (compatibilidad directa)
import OpenAI from "openai";
const client = new OpenAI({
baseURL: "http://localhost:11434/v1",
apiKey: "ollama", // cualquier string no vacío
});
async function ask(prompt: string): Promise<string> {
const response = await client.chat.completions.create({
model: "llama3.2",
messages: [{ role: "user", content: prompt }],
});
return response.choices[0].message.content ?? "";
}
const answer = await ask("Genera un schema Zod para un usuario con nombre y email");
console.log(answer);Nota: El
awaiten nivel superior requiere ESM. Añade"type": "module"en tupackage.jsono usa extensión.mts.
El prompt del ejemplo genera un schema Zod. Si quieres dominar la validación de datos con TypeScript para estos pipelines, el curso de Zod cubre exactamente ese flujo con ejemplos reales.
Con el cliente nativo de Ollama
import { Ollama } from "ollama";
const ollama = new Ollama({ host: "http://localhost:11434" });
// Respuesta completa
const response = await ollama.chat({
model: "qwen2.5-coder",
messages: [
{
role: "user",
content: "Escribe una función TypeScript que valide un email con regex",
},
],
});
console.log(response.message.content);
// Streaming
const stream = await ollama.chat({
model: "qwen2.5-coder",
messages: [{ role: "user", content: "Explica el patron Repository" }],
stream: true,
});
for await (const chunk of stream) {
process.stdout.write(chunk.message.content);
}Instala el cliente oficial:
npm install ollama
# o con bun
bun add ollamaCambiar entre local y nube con una variable de entorno
Este patrón es el que más uso en proyectos reales — permite alternar entre Ollama y OpenAI sin cambiar código:
import OpenAI from "openai";
const isLocal = process.env.USE_LOCAL_LLM === "true";
const client = new OpenAI({
baseURL: isLocal ? "http://localhost:11434/v1" : "https://api.openai.com/v1",
apiKey: isLocal ? "ollama" : process.env.OPENAI_API_KEY,
});
const model = isLocal ? "llama3.2" : "gpt-4o-mini";Con USE_LOCAL_LLM=true en desarrollo y la variable desactivada en producción, tienes el mejor de los dos mundos sin duplicar lógica. Esta es exactamente la clase de arquitectura que trabajamos en el curso Construye con IA, donde construimos productos completos con IA desde la especificación hasta el despliegue.
FAQ — Preguntas frecuentes sobre modelos IA en local
¿Qué hardware necesito para correr modelos IA en local?
Para modelos de 7B parámetros necesitas un mínimo de 8 GB de RAM y cualquier CPU moderna (últimos 5 años). Con GPU dedicada (NVIDIA o Apple Silicon) la inferencia es entre 5x y 10x más rápida. Un MacBook Pro M2 con 16 GB corre llama3.1:8b sin problemas. Para modelos de 70B necesitas al menos 64 GB de RAM o una GPU con suficiente VRAM.
¿Son los modelos locales comparables a GPT-4o o Claude?
No para tareas complejas de razonamiento multi-paso o generación de código sofisticado. Pero para clasificación, resumen, extracción de información estructurada, generación de texto simple y asistencia en código básico, modelos como qwen2.5-coder:7b o llama3.1:8b son más que suficientes. La brecha se ha reducido mucho en el último año.
¿Puedo usar Ollama en un servidor de CI/CD?
Sí. Ollama funciona en Linux sin cabecera y puede correr en Docker. El caso de uso más habitual: un runner de GitHub Actions con un runner self-hosted que tiene Ollama instalado para ejecutar checks de calidad de código o validaciones automáticas sin coste por llamada.
¿Cuánto espacio en disco ocupan los modelos?
Depende del modelo y la cuantización. llama3.2:3b ocupa unos 2 GB. llama3.1:8b unos 5 GB. llama3.3:70b alrededor de 40 GB. Ollama descarga versiones cuantizadas (Q4 por defecto) que reducen el tamaño a la mitad aproximadamente manteniendo el 90–95% de la calidad del modelo original.
¿Qué diferencia hay entre Ollama y LM Studio?
Ollama es una herramienta CLI-first, sin interfaz gráfica, pensada para integración en scripts y aplicaciones. LM Studio tiene una UI de escritorio con chat visual, gestor de modelos y comparador integrado. Ambas exponen una API local compatible con OpenAI. Si eres developer y quieres integrar el modelo en código, Ollama. Si quieres explorar modelos visualmente o presentarlos a stakeholders, LM Studio.
¿Puedo hacer fine-tuning de modelos con Ollama?
Ollama no está diseñado para fine-tuning. Su función es servir modelos, no entrenarlos. Para fine-tuning de modelos open source necesitas herramientas como Unsloth, LoRA con Hugging Face o plataformas como Together AI y Replicate. Ollama puede servir después el modelo fine-tuneado si lo exportas en formato GGUF.
¿Es seguro usar modelos locales en producción?
Depende del caso. Para un servicio interno o una herramienta de developer experience, perfectamente. Para un producto con miles de usuarios concurrentes, los modelos locales tienen limitaciones de escalabilidad obvias: un solo servidor solo puede atender las peticiones que su hardware permite procesar en paralelo. En ese escenario, la nube escala horizontalmente de forma que local no puede igualar.
¿Cómo elijo entre los modelos disponibles en Ollama?
Empieza con llama3.2:3b para validar el flujo de tu aplicación (descarga rápida, responde rápido). Sube a llama3.1:8b o qwen2.5-coder:7b cuando necesites mejor calidad. Si tu máquina tiene 32 GB+ de RAM, phi4:14b o gemma3:27b son excelentes opciones intermedias antes de saltar a los modelos de 70B.
Para ir más lejos
Si estás construyendo productos con IA — integrando modelos IA en local en pipelines completos, agentes y herramientas que lleguen a usuarios reales — el siguiente paso es estructurar esa arquitectura desde el principio.
El post sobre CLAUDE.md: el system prompt de tu proyecto explica cómo dar contexto permanente al agente. Clean Architecture en frontend con IA muestra cómo mantener las capas limpias cuando el agente genera código. Y si te preguntas hacia dónde va todo esto profesionalmente, la guía sobre qué es un Agentic Engineer cierra el mapa.
En Dominicode Labs encontrarás proyectos completos, recursos avanzados y una comunidad de developers que están exactamente en esa fase: construyendo con IA en producción, no en tutoriales de YouTube.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.
Leave a Reply