Durante casi diez años cobré a final de mes. Sin falta, sin sorpresas, sin ansiedad. Y durante casi diez años pensé que eso era la estabilidad.
Lo que no vi durante esos años es que el salario tiene un techo. Puedes mejorar, conseguir un aumento del 10%, cambiar de empresa y pegar un salto del 20%. Pero la relación entre tu esfuerzo y tu ingreso siempre es lineal. Das 40 horas, recibes X. Das 60 horas, recibes X igualmente — el salario no premia el esfuerzo extra, premia la presencia.
El día que entendí eso, empecé a construir algo diferente.
Hoy, parte de lo que gano viene de cursos que grabé hace tres años. Parte viene de una comunidad con membresía mensual. Parte viene de proyectos donde la IA me permite hacer el trabajo de un equipo pequeño en la mitad del tiempo. No es magia. No ocurrió de un mes al siguiente. Pero la diferencia estructural con un salario fijo es real y es enorme.
Si eres developer y quieres ganar dinero en internet como developer — no como influencer, no como coach de productividad, sino usando lo que ya sabes — estas son las tres formas que yo he visto funcionar en 2026.
1. Cursos técnicos: cómo generar ingresos pasivos como developer
Los cursos técnicos son la forma más asimétrica de monetizar conocimiento: produces el contenido una vez y genera ingresos recurrentes sin trabajo adicional por cada venta.
Es el modelo que yo empecé primero y el que más me ha enseñado sobre la diferencia entre tiempo y activo.
La lógica es simple: tienes conocimiento técnico que alguien más necesita. En lugar de explicárselo una vez en una reunión — y que te paguen por esa hora —, lo grabas, lo estructuras, y lo vendes 10.000 veces sin hacer nada más.
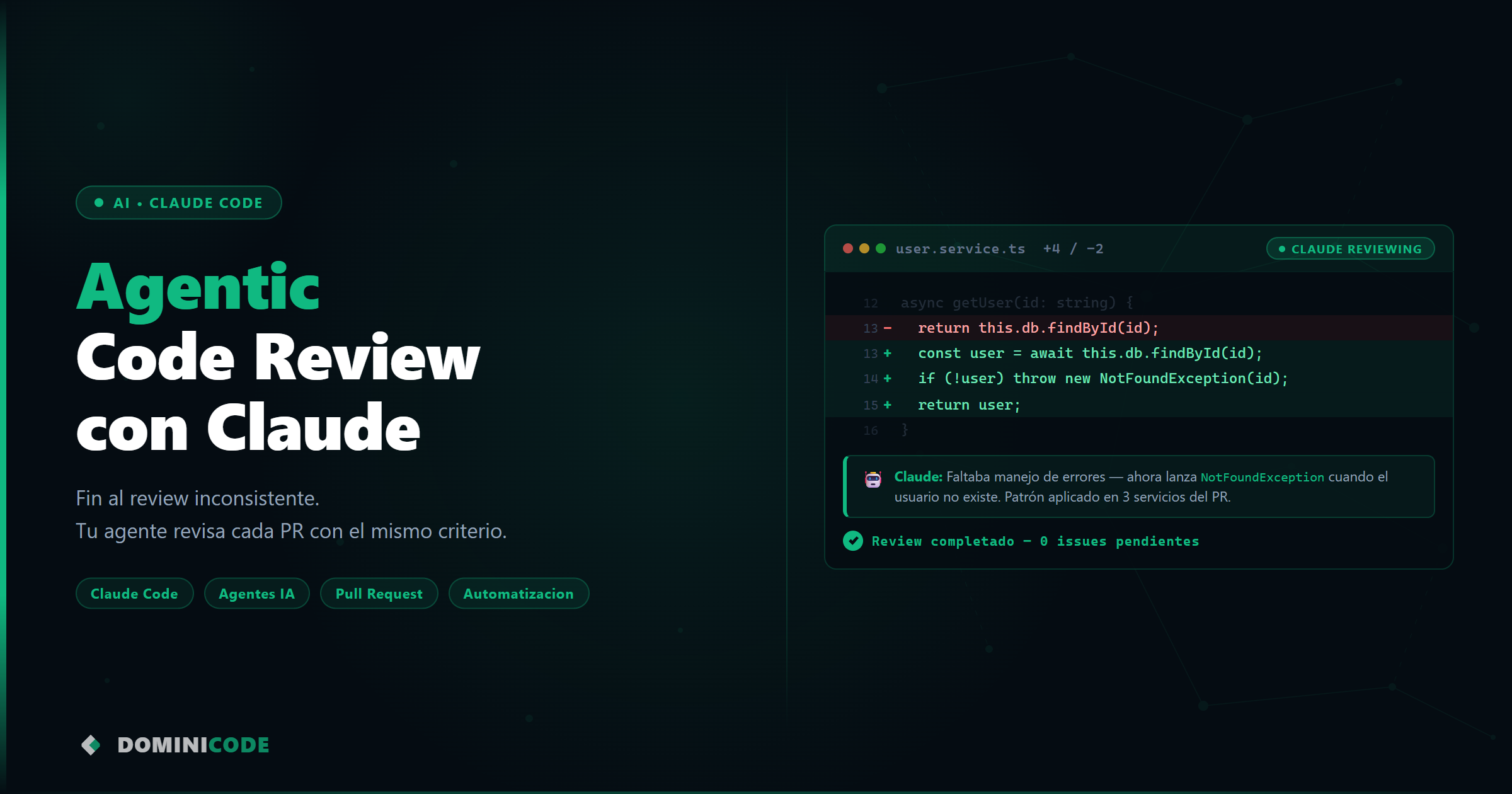
Eso es lo que pasa con mis cursos en Udemy: el de Angular Moderno, el de Testing, el de Zod, el de Claude Code. Los grabé. Siguieron vendiendo. El trabajo ya está hecho.
Pero hay algo que casi nadie dice sobre esto: los primeros meses son duros. Tu primer curso no va a generar €3.000 el primer mes. Va a generar €80 y te va a parecer poco para el esfuerzo que pusiste. La clave está en entender que no estás cobrando por ese mes — estás construyendo un activo que va a seguir funcionando.
Algunos números reales para que tengas expectativas honestas:
- Un curso en Udemy puede generar entre €50 y €500/mes en sus primeros meses, dependiendo del nicho y la demanda.
- A medida que acumulas reseñas y estudiantes, crece de forma orgánica sin que hagas nada nuevo.
- Si tienes 3 o 4 cursos, los ingresos se suman. Eso es lo que marca la diferencia.
Lo que necesitas para empezar: saber algo que otros developers necesiten aprender, tener un micrófono decente, y la disciplina para terminar lo que empiezas. No necesitas ser el mejor del mundo en el tema — necesitas saber más que tu alumno objetivo y saber explicarlo con claridad.
2. SaaS con IA: el modelo que un developer puede construir solo
Un SaaS pequeño con IA es un producto digital que resuelve un problema concreto y cobra de forma recurrente — y en 2026, un developer puede construirlo solo en días, no en meses.
El problema del SaaS clásico era el tiempo: meses para llegar a un MVP, y eso si tenías equipo. Con Claude Code, Cursor o agentes bien configurados, ese cuello de botella desaparece. No porque la IA programe por ti — sino porque elimina la fricción entre lo que sabes hacer y el tiempo que tardas en hacerlo.
El modelo que funciona no es el "construyo el próximo Notion" — eso es una trampa. El modelo que funciona es: identifica un proceso repetitivo y tedioso que alguien paga por resolver, y cóbralo como herramienta.
Ejemplos concretos que he visto en la comunidad de Dominicode Labs:
- Una herramienta que genera contratos de freelance desde una plantilla y los envía por email: €9/mes.
- Un pequeño dashboard que consolida métricas de varias plataformas para agencias: €29/mes.
- Un agente que revisa PRs de código y genera un resumen para el equipo: €19/mes por organización.
Ninguno de estos es revolucionario. Todos resuelven un problema real. Y todos tienen un modelo de cobro recurrente que convierte el trabajo de una semana en un ingreso mensual.
El umbral de entrada es bajo. El único requisito es que seas capaz de hablar con clientes potenciales antes de escribir la primera línea de código — algo que a los developers nos cuesta más de lo que queremos admitir.
3. Consultoría técnica con IA: cobra más, trabaja igual
La consultoría técnica multiplicada por IA no es el freelancing clásico: es usar agentes e IA para hacer el trabajo de varios developers en el tiempo de uno, y cobrar en consecuencia.
El freelancing clásico tiene el mismo problema que el salario: sigues cambiando tiempo por dinero. Tienes 40 horas. Las vendes. No puedes vender 80.
Lo que ha cambiado en 2026 es que la IA te permite hacer el trabajo de dos o tres developers en el tiempo de uno. Si sabes configurar agentes, si sabes delegar las partes repetitivas a Claude Code o a flujos de n8n, si sabes qué parte del trabajo requiere tu criterio humano y qué parte puede automatizarse — puedes cobrar como equipo y trabajar como individuo.
Eso no es trampa. Es eficiencia. Los clientes pagan por resultados, no por horas.
Hay dos variantes concretas de este modelo:
Proyectos de implementación acelerada. Un cliente necesita integrar una API, construir un backend, migrar un sistema. Antes, eso costaba tres meses y tres developers. Tú lo entregas en tres semanas con IA y cobras el 60% de lo que habría costado el equipo. Todos ganan.
Automatización de procesos de negocio con retención mensual. Esto es lo que más escala. Entras en una empresa, identificas los procesos manuales y repetitivos — reportes, emails, validaciones de datos, flujos entre herramientas — y los automatizas con n8n, agentes o scripts. Cobras un fee mensual por mantenimiento y mejoras. Es MRR sin necesidad de un producto propio.
Este modelo requiere que salgas de la zona de confort técnica y entres en conversaciones de negocio. Requiere entender el problema del cliente antes de proponer la solución. Pero si lo haces bien, puedes tener tres o cuatro clientes recurrentes que juntos superen con creces cualquier salario.
Los tres modelos comparados
| Modelo | Esfuerzo inicial | Ingresos típicos (6 meses) | Requiere audiencia previa |
|---|---|---|---|
| Cursos técnicos | Alto | €50–€500/mes por curso | No, pero acelera mucho |
| SaaS con IA | Medio | €9–€29/usuario/mes | No |
| Consultoría con IA | Bajo | €2.000–€8.000/mes por cliente | No |
Los tres no son mutuamente excluyentes. Yo los tengo los tres activos en paralelo. No empecé con los tres a la vez — eso habría sido demasiado. La secuencia que yo recomendaría:
- Empieza por los cursos. El tiempo de producción es alto, pero el activo dura años y te posiciona como referente en tu nicho.
- Cuando tengas audiencia, lanza algo pequeño de pago recurrente. Puede ser una comunidad, una herramienta, un recurso. En mi caso fue Dominicode Labs.
- Usa la IA para multiplicar tu capacidad en proyectos de consultoría mientras los otros dos modelos generan ingreso pasivo.
Ninguno de estos caminos es pasivo desde el primer día. El trabajo inicial es real. Pero la asimetría — lo que recibes a largo plazo versus lo que das en las primeras semanas — es lo que los hace estructuralmente distintos a un salario.
Si quieres empezar por aprender a construir con IA de forma que tenga sentido de negocio, en el curso Construye con IA cubrimos exactamente eso: cómo pasar de una idea a un producto real usando Claude Code con criterio. Y en el blog de Dominicode publicamos regularmente tutoriales técnicos sobre IA aplicada, agentes y desarrollo de producto.
Preguntas frecuentes
¿Cuánto tiempo se tarda en ganar dinero con un curso técnico?
Depende del nicho y de si ya tienes audiencia. Con audiencia desde el primer mes puedes generar ingresos reales. Sin audiencia, cuenta entre 3 y 6 meses para que el curso empiece a tener tracción orgánica en Udemy. Los primeros meses el ingreso es bajo — la clave es no abandonar en ese tramo.
¿Necesito una empresa para ofrecer consultoría con IA?
No para empezar. Puedes operar como autónomo o freelance desde el primer día. La estructura legal depende de tu país y de los volúmenes que manejes. Lo que sí necesitas desde el principio es un contrato claro y saber articular el valor que entregas en términos de negocio, no de horas trabajadas.
¿Qué nicho de SaaS tiene más demanda en 2026?
Los que más estoy viendo: automatización de procesos administrativos para pymes, herramientas de generación y gestión de contenido, y dashboards de consolidación de datos para equipos pequeños que no pueden permitirse soluciones enterprise. Ninguno es glamuroso. Todos tienen clientes dispuestos a pagar.
¿Puedo hacer las tres cosas a la vez desde el principio?
Técnicamente sí, pero no lo recomiendo. Intentar hacer tres cosas a la vez en paralelo garantiza que ninguna llegue a ningún sitio. Elige una, ponla a funcionar, y cuando genere ingreso estable — aunque sea pequeño — añade la siguiente. La consistencia gana a la ambición dispersa.
¿Con qué nivel técnico se puede empezar?
Para los cursos: nivel intermedio-senior con al menos 3-4 años de experiencia en un área concreta. Para el SaaS con IA: igual — necesitas criterio técnico para tomar decisiones de arquitectura, la IA no las toma por ti. Para la consultoría: cuanto más experiencia tengas en sistemas reales, más valor puedes ofrecer.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.