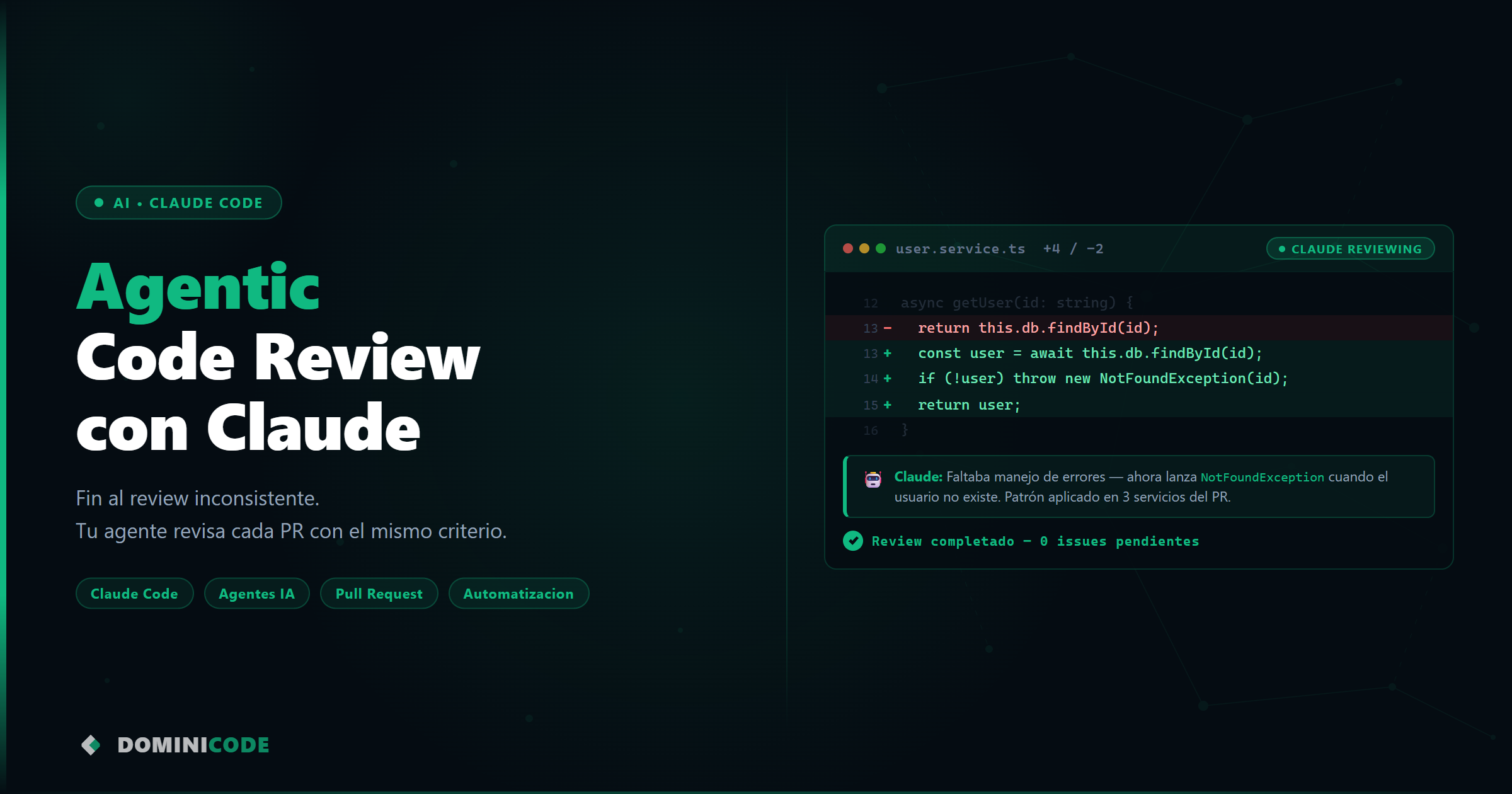
Hace un año integré una búsqueda semántica en un proyecto SaaS. El cliente quería que los usuarios encontraran artículos aunque escribieran con sinónimos, con errores ortográficos, o en un idioma distinto al del contenido.
La solución: tres líneas de TypeScript llamando a algoritmos de machine learning vía la API de OpenAI. Funcionó en una tarde.
Pero el cliente preguntó algo que me dejó sin respuesta inmediata: "¿Qué hace exactamente ese modelo por dentro?". Y yo, con 15 años de experiencia en desarrollo, tuve que admitir que no tenía una respuesta clara más allá de "convierte texto en números".
Ese hueco me molestó. No porque necesitara implementar los algoritmos desde cero, sino porque cuando no entiendes qué hay debajo del capó, tomas peores decisiones: eliges el modelo equivocado, debuggeas en la dirección incorrecta, o diseñas una arquitectura que no escala.
Este post es lo que me hubiera gustado leer ese día. Los algoritmos de machine learning explicados para developers web — sin fórmulas, sin Python, sin pretender que vas a ser data scientist.
Tres familias que lo explican todo
Los algoritmos de machine learning son procedimientos que permiten a un sistema aprender patrones a partir de datos, sin que un programador defina explícitamente las reglas. En lugar de escribir if (spam) { ... }, le muestras miles de emails al modelo y él deduce las reglas solo.
Hay tres formas fundamentales en que ocurre ese aprendizaje:
Aprendizaje supervisado. Le das al modelo ejemplos con respuesta correcta. "Este email es spam. Este otro no lo es." El modelo aprende el patrón. Cuando llega un email nuevo, predice a cuál categoría pertenece. Úsalo cuando tienes datos etiquetados y una tarea de predicción o clasificación concreta.
Aprendizaje no supervisado. No hay respuestas correctas. Le das datos sin etiquetar y el modelo encuentra estructura por sí solo. "Estos usuarios tienen comportamiento parecido. Estos otros también. Hay tres grupos." Úsalo cuando quieres descubrir patrones que no conoces de antemano — clustering de usuarios, detección de anomalías.
Reinforcement learning. El modelo aprende por ensayo y error: hace una acción, recibe una recompensa o penalización, ajusta. Es cómo funcionan los modelos de juegos, pero también cómo se afinan los LLMs para que sus respuestas sean más útiles (RLHF — Reinforcement Learning from Human Feedback).
Con esto en mente, los algoritmos concretos tienen contexto.
Los algoritmos de machine learning que te importan como developer
Resumen antes de entrar en detalle — ninguno lo vas a implementar tú:
| Algoritmo | Tipo | Cuándo lo usas en web | ¿Lo implementas? |
|---|---|---|---|
| Regresión logística | Supervisado | Scoring, predicción de churn | No — API |
| Random Forest | Supervisado | Moderación, detección de fraude | No — API |
| K-Means | No supervisado | Clustering de usuarios | No — API |
| Redes neuronales | Supervisado | Base de embeddings, clasificación | No — modelos preentrenados |
| Embeddings | Supervisado | Búsqueda semántica, recomendaciones | No — OpenAI/HuggingFace |
| Transformers | Supervisado | LLMs, generación, clasificación avanzada | No — API |
Regresión lineal y logística
Son los más simples. La regresión lineal predice un número: "¿Cuánto va a costar este apartamento?" La logística predice una probabilidad: "¿Hay un 87% de probabilidad de que este usuario cancele su suscripción este mes?"
No las vas a implementar, pero las vas a encontrar en APIs de scoring, en features de predicción de churn, en sistemas de precios dinámicos. Cuando una API te devuelve un score: 0.87, probablemente hay una regresión logística detrás.
Árboles de decisión y Random Forest
Imagina una serie de preguntas de sí/no encadenadas. "¿El usuario tiene más de 30 días de cuenta? ¿Ha hecho al menos una compra? ¿Abrió el último email?" Cada camino lleva a una predicción. Eso es un árbol de decisión.
Random Forest toma cientos de árboles distintos y combina sus respuestas. El resultado es más robusto y menos propenso a overfitting que un solo árbol.
Son los algoritmos detrás de sistemas de moderación de contenido basados en reglas aprendidas, de detección de fraude, de sistemas de recomendación básicos.
K-Means (clustering)
K-Means agrupa datos en K clusters. Tú dices cuántos grupos quieres (K), el algoritmo encuentra cuáles puntos de datos pertenecen a cada grupo.
Como developer web, esto aparece en sistemas de personalización: "Usuarios que actúan como tú también compraron esto." No hay etiquetas previas — el modelo descubre los segmentos solo.
Redes neuronales
Aquí empieza lo que la gente llama "deep learning". Una red neuronal es una cadena de capas matemáticas que transforman una entrada (texto, imagen, audio) en una salida (una clasificación, un número, un vector).
Lo importante para entenderlas no es la matemática — es el concepto de representación. Cada capa aprende a representar la entrada de una forma más abstracta que la anterior. La primera capa de un modelo de visión detecta bordes. La siguiente detecta formas. La siguiente detecta objetos. Ningún programador definió esas representaciones: emergieron del entrenamiento.
Embeddings — el algoritmo que ya usas
Los embeddings son el resultado de pasar texto (o imágenes, o audio) por una red neuronal especializada. La salida es un vector de números — típicamente de 768 a 3072 dimensiones.
La magia es que los vectores capturan significado semántico. "Perro" y "can" producen vectores muy cercanos en ese espacio de alta dimensión. "Perro" y "hipoteca" producen vectores lejanos.
Esto es lo que permite la búsqueda semántica: conviertes tu query en un vector, comparas contra los vectores de tu base de datos, y devuelves los más cercanos. No importa si el usuario escribió "gato" y el documento dice "felino" — los vectores están cerca.
Transformers — la arquitectura detrás de los LLMs
Un Transformer es una arquitectura de red neuronal diseñada para procesar secuencias. El mecanismo clave se llama "atención" (attention): permite que el modelo, al procesar una palabra, preste atención a otras palabras del contexto según su relevancia.
"El banco estaba lleno de peces" vs "El banco rechazó mi solicitud". La misma palabra "banco", significado completamente distinto. El mecanismo de atención resuelve esto mirando el contexto completo de la frase.
GPT, Claude, Llama y Gemini usan Transformers como arquitectura base. Los modelos de embeddings de OpenAI también son Transformers, pero optimizados para producir buenas representaciones vectoriales en lugar de generar texto.
Cuándo le importan al developer web
No necesitas un data scientist para beneficiarte de ML. Estas son las integraciones más comunes en proyectos web reales. Puedes ver más ejemplos aplicados en el blog de Dominicode.
Búsqueda semántica. Reemplaza o complementa la búsqueda por palabras clave. Los embeddings convierten queries y documentos en vectores, y una base de datos vectorial (Pinecone, pgvector, Supabase Vector) hace el matching por similitud coseno.
Moderación de contenido. Clasifica si un texto es tóxico, si una imagen es apropiada, si un comentario viola normas. HuggingFace tiene modelos de clasificación listos para usar via API — zero setup del lado del ML.
Recomendaciones. Clustering de usuarios por comportamiento o embeddings de productos para "productos similares". No necesitas construir un sistema de recomendación desde cero — embeddings + similitud coseno es suficiente para empezar.
Extracción de información. Parsear emails, facturas, formularios en lenguaje natural. Un LLM con un prompt bien estructurado hace esto mejor que cualquier regex que vayas a escribir.
TypeScript en la práctica
Aquí es donde todo esto se vuelve concreto. No vas a implementar K-Means. Vas a llamar a una API que usa K-Means internamente. Pero entender qué hace el algoritmo te ayuda a saber qué esperar y qué debuggear.
Embeddings con OpenAI
import OpenAI from "openai";
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
async function getEmbedding(text: string): Promise<number[]> {
const response = await client.embeddings.create({
model: "text-embedding-3-small",
input: text,
});
return response.data[0].embedding; // Vector de 1536 dimensiones
}
// Similitud coseno entre dos vectores
function cosineSimilarity(a: number[], b: number[]): number {
const dot = a.reduce((sum, val, i) => sum + val * b[i], 0);
const magA = Math.sqrt(a.reduce((sum, val) => sum + val * val, 0));
const magB = Math.sqrt(b.reduce((sum, val) => sum + val * val, 0));
return dot / (magA * magB);
}
// Búsqueda semántica básica
// En producción: usar batching o rate limiting para evitar errores 429 de la API
async function semanticSearch(query: string, documents: string[]) {
const queryVector = await getEmbedding(query);
const docVectors = await Promise.all(documents.map(getEmbedding));
const scores = docVectors.map((vec, i) => ({
document: documents[i],
similarity: cosineSimilarity(queryVector, vec),
}));
return scores.sort((a, b) => b.similarity - a.similarity);
}
const docs = [
"Cómo configurar un servidor NestJS",
"Recetas de cocina italiana",
"Deploying Node.js to production",
];
const results = await semanticSearch("backend con Node", docs);
console.log(results[0]); // { document: "Deploying Node.js...", similarity: 0.89 }
Referencia oficial: OpenAI Embeddings API.
Clasificación con HuggingFace Inference API
const HF_TOKEN = process.env.HF_TOKEN;
const MODEL = "cardiffnlp/twitter-roberta-base-sentiment-latest";
interface ClassificationResult {
label: string;
score: number;
}
async function classifySentiment(text: string): Promise<ClassificationResult[]> {
const response = await fetch(
`https://api-inference.huggingface.co/models/${MODEL}`,
{
method: "POST",
headers: {
Authorization: `Bearer ${HF_TOKEN}`,
"Content-Type": "application/json",
},
body: JSON.stringify({ inputs: text }),
}
);
// Si el modelo lleva tiempo sin uso, la primera respuesta puede tardar
// 20-30 segundos con { error: "Model is currently loading" } — reintentar.
const data = await response.json();
return data[0] as ClassificationResult[];
}
const result = await classifySentiment("Este producto es increíble!");
// [{ label: "POSITIVE", score: 0.97 }, { label: "NEUTRAL", score: 0.02 }, ...]
if (result[0].label === "NEGATIVE" && result[0].score > 0.85) {
// Marcar para revisión manual
}
Referencia oficial: HuggingFace Inference API.
Dos ejemplos, dos APIs reales, cero instalación de librerías de ML. El algoritmo corre en la nube. Tú consumes el resultado y construyes producto.
Si quieres explorar estas integraciones dentro de un flujo completo — desde la idea hasta el producto funcionando — en el curso Construye con IA cubrimos exactamente esta capa: cómo conectar modelos de ML reales a una arquitectura de producto sin convertirte en data scientist. También publicamos tutoriales y ejemplos en el canal de YouTube de Dominicode.
La decisión que cambia todo
Entender estos algoritmos no significa que vayas a entrenar modelos. Significa que cuando eliges entre una búsqueda por palabras clave y una búsqueda semántica, sabes exactamente qué estás eligiendo y por qué.
Significa que cuando un modelo de clasificación te devuelve un score bajo, sabes si el problema está en el modelo, en los datos de entrada, o en cómo estás interpretando el output.
Significa que cuando alguien en tu equipo dice "usemos ML para esto", puedes hacer las preguntas correctas: ¿supervisado o no supervisado? ¿Tienes datos etiquetados? ¿Qué métrica defines como éxito?
Los modelos los entrenan los data scientists. El producto lo construyes tú. Saber qué hay debajo del capó es lo que hace la diferencia entre un developer que consume IA y uno que la integra de forma inteligente.
En Dominicode Labs tenemos proyectos completos donde aplicamos estas integraciones en contextos reales — búsqueda semántica, pipelines con embeddings, agentes que usan clasificadores como herramientas. Si quieres ver el código funcionando, es donde empieza.
FAQ
¿Necesito saber matemáticas para usar algoritmos de machine learning como developer?
No para usarlos, sí para entenderlos en profundidad. La mayoría de las integraciones que harás como developer web consumen modelos ya entrenados via API. Saber qué hace el algoritmo — qué tipo de problema resuelve y qué output produce — es suficiente para tomar buenas decisiones de arquitectura. Si en algún momento necesitas afinar un modelo o interpretar métricas de entrenamiento, entonces sí vale la pena profundizar en la matemática.
¿Cuál es la diferencia entre un LLM y un modelo de embeddings?
Un LLM (como GPT-4 o Claude) está entrenado para generar texto: toma una secuencia de tokens y predice los siguientes. Un modelo de embeddings está optimizado para producir representaciones vectoriales del texto, capturando su significado semántico en un espacio de alta dimensión. Ambos usan arquitectura Transformer, pero con objetivos de entrenamiento distintos. Para búsqueda semántica, usa modelos de embeddings — son más baratos y específicos para esa tarea.
¿Cuándo debería usar TensorFlow.js en lugar de una API de ML?
TensorFlow.js tiene sentido cuando necesitas ejecutar inferencia en el cliente (sin enviar datos al servidor, por privacidad), cuando tienes latencia muy baja como requisito, o cuando quieres evitar costos de API a escala. El tradeoff es que los modelos disponibles para el navegador son más pequeños y menos potentes. Para la mayoría de proyectos web, una API de HuggingFace o OpenAI es la opción correcta hasta que tengas una razón específica para moverse al cliente.
¿Qué es el overfitting y por qué le importa al developer que consume modelos?
El overfitting ocurre cuando un modelo aprende demasiado bien los datos de entrenamiento y pierde capacidad de generalizar a datos nuevos. Como developer que consume un modelo ya entrenado, el overfitting se manifiesta como comportamiento inesperado: el modelo funciona bien en ejemplos estándar pero falla en casos edge de tu dominio específico. Si ves esto, la solución no es ajustar el código — es cambiar de modelo, hacer fine-tuning, o cambiar cómo preparas el input (prompt engineering, preprocesado de texto).
¿Qué base de datos debo usar para guardar y consultar embeddings?
Depende de tu stack. Si ya usas PostgreSQL o Supabase, la extensión pgvector añade soporte nativo para búsqueda por similitud coseno sin infraestructura adicional. Si necesitas escala masiva (millones de vectores con latencia sub-50ms), Pinecone o Weaviate son las opciones especializadas. Para prototipos o proyectos pequeños, guardar vectores en memoria con una búsqueda lineal es perfectamente válido mientras no superes los 10k documentos.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.