Un cliente me mandó su proyecto hace tres semanas. Llevaba dos meses usando Claude Code todos los días. El repositorio tenía 340 archivos. Tenía features. Tenía tests. El código compilaba.
Y no tenía ni idea de qué hacía el sistema.
Me preguntó: “¿Por qué cada vez que añado algo nuevo, rompo tres cosas que ya funcionaban?” La respuesta era visible desde el primer git log: llevaba dos meses pidiéndole a la IA que generara código sin decirle nunca qué estaba construyendo realmente. Cada prompt era una instrucción táctica. Nunca había una visión. Nunca un mapa.
Eso es Spec-Driven Development (SDD) al revés. Y en 2026, con agentes que pueden escribir mil líneas en minutos, la diferencia entre los dos modos es la diferencia entre un producto y un desastre con tests.
La IA no necesita que seas más rápido. Necesita que seas más claro.
La narrativa que se vende sobre el desarrollo con IA es esta: “ahora puedes construir el doble de rápido”. Es verdad. El problema es que construir el doble de rápido sin dirección no te lleva antes a destino — te lleva el doble de lejos en la dirección equivocada.
Los agentes de IA son ejecutores extraordinariamente potentes con cero criterio arquitectónico propio. Claude Code, GitHub Copilot, Cursor, cualquiera — siguen instrucciones. Si las instrucciones son vagas, el output es coherente localmente e incoherente globalmente. Cada archivo tiene sentido en sí mismo. El sistema entero no tiene sentido como conjunto.
El spec no es documentación. No es burocracia. Es la única forma de darle a un agente de IA el contexto suficiente para que sus decisiones locales sean coherentes con la visión global.
Sin spec, el agente está adivinando constantemente. Y adivina bien, frase a frase. Pero adivinar bien frase a frase no produce un párrafo con sentido — produce contenido que parece correcto y no lleva a ningún lado.
Qué es SDD y por qué no es lo que crees
Spec-Driven Development no es escribir documentación antes de programar. Eso es lo que la mayoría imagina y por lo que lo descartan: “ya tengo suficiente trabajo sin añadir Word docs al proceso”.
SDD es una metodología de tres artefactos que define qué construyes, cómo lo construyes y en qué orden lo construyes — antes de que un solo agente escriba una sola línea de código.
Los tres artefactos son:
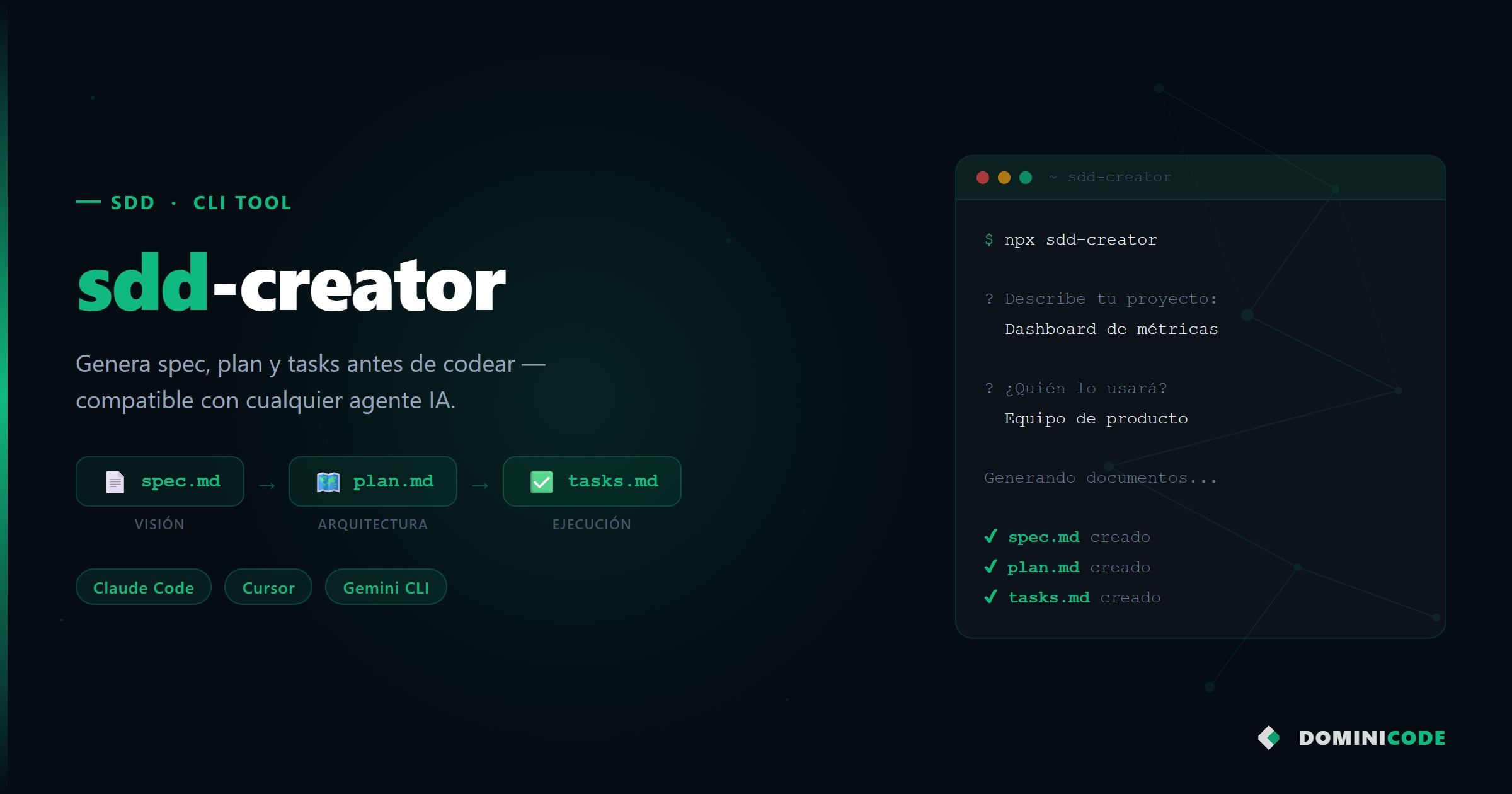
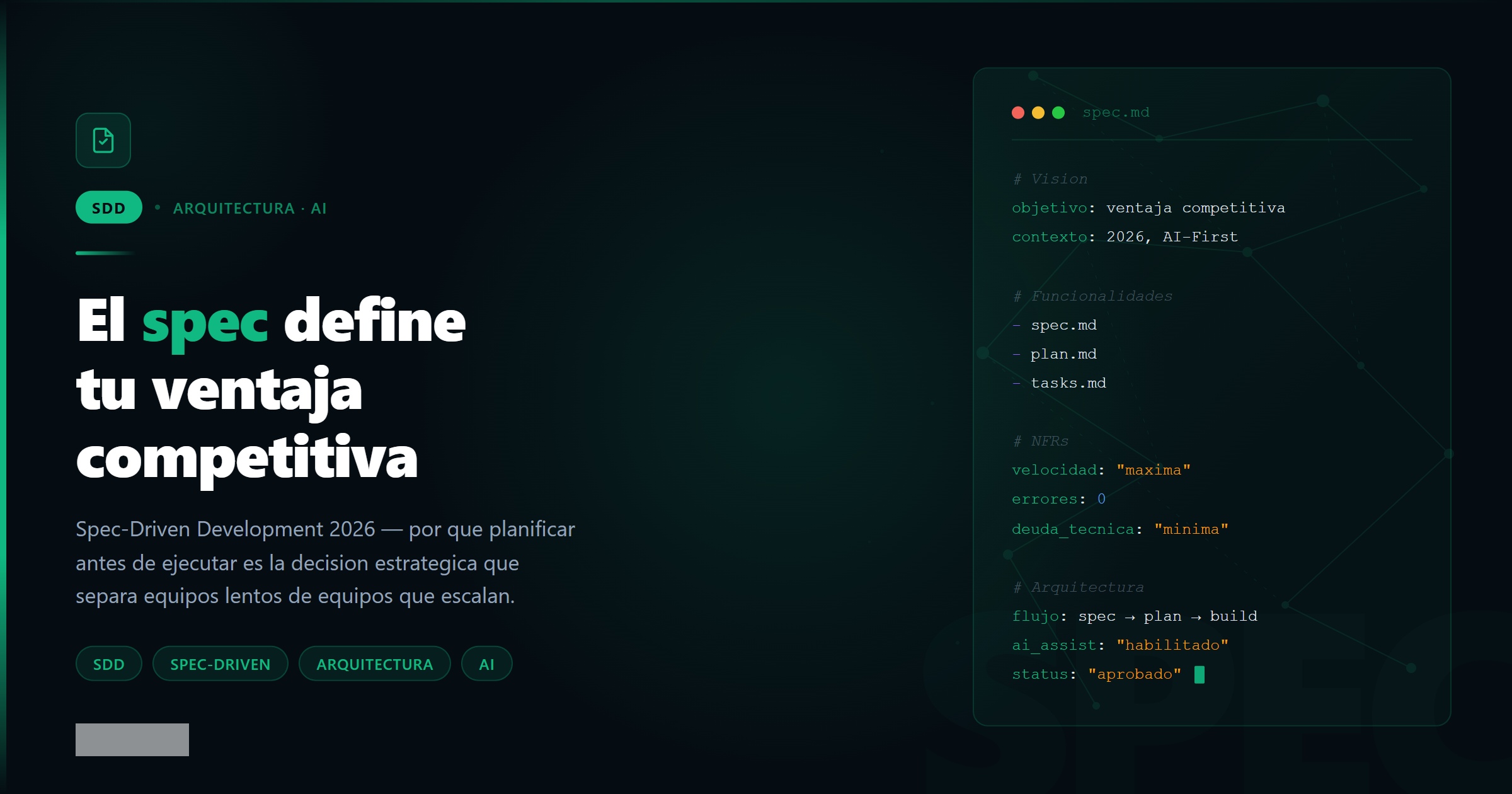
spec.md — el qué. La especificación estructurada del sistema. Tiene seis secciones fijas: Visión, Usuarios, Funcionalidades, Flujos, Arquitectura, NFRs. En total, tres o cuatro páginas que responden a la pregunta que ningún agente puede responder por ti: qué problema resuelves exactamente, para quién, y qué significa “hecho” en este proyecto.
plan.md — el cómo. El plan técnico por fases. No divide el trabajo en tareas sueltas — divide el trabajo en capas que tienen sentido en secuencia. Primero el dominio, después la infraestructura, después la UI. No al revés. El plan.md es el documento que evita que empieces por la pantalla de login cuando el sistema de autenticación aún no existe.
tasks.md — el orden. La lista de tareas ordenada para TDD. Cada tarea define qué test escribes primero y qué código lo hace pasar. El tasks.md convierte el plan en commits atómicos verificables. Cuando un agente ejecuta una tarea del tasks.md, el resultado es predecible: un test verde y un incremento de funcionalidad real.
Estos tres documentos no tardan tres días en escribirse. Con el skill /dominicode-sdd-spec-creator en Claude Code (disponible para miembros de Dominicode Labs), la estructura completa se genera en minutos a partir de una descripción del proyecto. Lo que tarda tiempo es pensar — y ese tiempo es exactamente el que te ahorra deuda técnica después.
Antes vs después: el mismo proyecto, dos formas de empezar
Hace unos meses construí un sistema de gestión de contenido para automatizar la publicación en múltiples canales. El proyecto tenía integraciones con tres APIs externas, lógica de colas, transformaciones de formato y un dashboard de seguimiento.
Sin SDD (como lo hubiera hecho en 2022): Habría abierto el editor, creado una carpeta src/, y empezado por la parte que más me apetecía — probablemente el dashboard. A las dos semanas tendría un dashboard bonito conectado a datos hardcodeados, una integración con una API que funcionaba en happy path, y ninguna certeza de cómo conectar las piezas. Cada decisión técnica habría sido local, sin visión del sistema completo.
Con SDD: Antes de escribir código, escribí el spec.md. La sección de Flujos me forzó a pensar en qué pasa cuando una API falla en mitad de una publicación — algo que no habría considerado hasta toparme con el bug en producción. La sección de NFRs me hizo definir qué latencia máxima era aceptable para el sistema de colas. La sección de Arquitectura me hizo elegir entre evento-driven y polling antes de escribir nada — no a mitad del proyecto cuando cambiar de dirección cuesta semanas.
El spec.md tardó dos horas. El plan.md, una hora más. El tasks.md, otra hora.
Cuatro horas de especificación que eliminaron tres semanas de refactoring posterior.
Cuando empecé a usar Claude Code en el proyecto, el agente tenía el spec.md en el contexto. Cada decisión técnica que tomaba era coherente con la arquitectura definida. No porque el LLM sea mágicamente más inteligente con un documento — sino porque el documento le daba información que de otra forma no tenía.
El spec como brújula del agente
Este es el cambio de mentalidad que más cuesta hacer: el spec no es para ti. Es para el agente.
Cuando llevas quince años programando, tu cabeza tiene el contexto del proyecto. Sabes por qué elegiste ese patrón. Sabes qué módulo toca qué. Sabes los trade-offs que hiciste en la semana dos. Ese contexto vive en tu cabeza y lo das por supuesto.
El agente no tiene nada de eso. Sin contexto explícito, cada sesión empieza desde cero. Cada prompt es una petición descontextualizada si no le das el marco. Sin spec, el agente responde a lo que le preguntas — no a lo que necesitas construir.
Con el spec.md en contexto, el agente puede hacer preguntas que de otra forma no haría: “esta funcionalidad que me pides entra en conflicto con el flujo de usuario número tres que está en el spec — ¿quieres cambiar el flujo o ajustar la funcionalidad?”. Esa pregunta vale más que mil líneas de código generado sin contexto.
Esta es exactamente la lógica detrás del libro Spec-Driven Development — no es un manual de documentación, es una metodología diseñada para que el agente tenga suficiente contexto para tomar decisiones correctas sin que tú estés micromanageando cada prompt.
Por qué el spec te protege del vibe coding
El vibe coding no es programar con IA. Es programar con IA sin criterio. Hay developers que publican proyectos enteros generados en un fin de semana. Impresionante en superficie. Inutilizable en producción.
El problema del vibe coding no es la velocidad — es la ausencia de coherencia acumulada. Cada prompt genera código coherente con el prompt anterior, pero nadie garantiza que el sistema resultante sea coherente con la intención original. A las cuatro horas de vibe coding, el proyecto tiene forma de algo pero no tiene diseño. Tiene features pero no tiene arquitectura.
Lo que se acumula en silencio no es código malo — es deuda técnica agéntica. El tipo de deuda que no se ve en los tests porque los tests también los generó el agente sin un contrato claro de qué probar. El tipo de deuda que explota cuando intentas añadir la feature número veinte sobre una base que asumió implícitamente cosas que nunca se definieron.
Para entender por qué la arquitectura de tus agentes necesita un spec detrás, te recomiendo el post sobre agentic harness: por qué la spec y la arquitectura no bastan.
SDD es el antídoto no porque ralentice el desarrollo. Lo acelera — pero acelera el desarrollo en la dirección correcta. La spec es el contrato que el agente respeta en cada iteración. El plan es la secuencia que evita que construyas la décima planta antes de los cimientos. El tasks.md son los commits que puedes revisar, aprobar y revertir si algo no cuadra.
Con SDD, el vibe coding se convierte en agile coding con contexto — velocidad de agente, criterio de arquitecto.
Cómo empezar con SDD en Claude Code hoy
Si tienes Claude Code y quieres aplicar SDD en tu próximo proyecto, el proceso es directo:
- Describe tu proyecto en lenguaje natural — qué construyes, para quién, qué problema resuelve.
- Ejecuta el skill
/dominicode-sdd-creator— genera spec.md, plan.md y tasks.md en pocos minutos (disponible en Dominicode Labs). - Revisa el spec antes de tocar código — es el momento de pensar, no después.
- Añade el spec.md al contexto de Claude Code con
@spec.mdal inicio de cada sesión de desarrollo — la documentación oficial de Claude Code explica cómo gestionar el contexto entre sesiones. - Trabaja el tasks.md en secuencia — un task, un test, un commit.
El skill no reemplaza tu pensamiento. Te obliga a pensar antes de que sea costoso cambiar de dirección.
El post sobre SDD Creator, la herramienta CLI muestra exactamente cómo se genera la estructura automáticamente.
Si quieres ver cómo se aplica esto en un proyecto real de principio a fin — desde la spec inicial hasta el deploy — es exactamente lo que trabajamos en el curso Construye con IA: no tutoriales sueltos de herramientas, sino el proceso completo de construir un producto con IA de forma que funcione en producción.
El spec como ventaja competitiva real
Hay algo que nadie dice sobre SDD en 2026 y que merece decirse.
En un mundo donde cualquier developer puede generar código a gran velocidad con IA, la diferencia competitiva no está en quién genera más rápido. Está en quién sabe exactamente qué construir y por qué.
El spec es donde vive esa ventaja. No en el prompt. No en la elección del modelo. En la claridad con la que defines el problema antes de que empiece la ejecución.
Los developers que entienden esto ya no compiten con los que “usan IA para programar más rápido”. Son una categoría diferente: developers que combinan criterio técnico con capacidad de ejecución agéntica. El spec es la expresión concreta de ese criterio.
Dentro de doce meses, los equipos que hayan integrado SDD en su workflow tendrán bases de código mantenibles, documentación generada como efecto colateral del proceso, y la capacidad de incorporar nuevos agentes o nuevos developers sin que el proyecto colapse. Los que sigan con vibe coding habrán reescrito el proyecto tres veces.
FAQ
¿SDD no es simplemente documentación con otro nombre?
No. La documentación describe lo que existe. El spec define lo que va a existir — antes de que exista. La diferencia no es semántica: la documentación se escribe después y siempre está desactualizada. El spec se escribe antes y guía la implementación. Si el spec y el código divergen durante el desarrollo, es señal de que hay una decisión técnica que tomar conscientemente — no de que el documento esté equivocado.
¿Cuánto tiempo tarda escribir el spec de un proyecto real?
Depende del proyecto. Para un MVP de funcionalidad acotada, entre dos y cuatro horas. Para un sistema con múltiples integraciones y flujos complejos, un día. El punto de referencia útil: si el spec tarda más de un día en escribirse, es señal de que el proyecto no está suficientemente definido para empezar a construirlo — y ese es el momento exacto en que el spec te está salvando, no ralentizando.
¿Se puede aplicar SDD a proyectos que ya existen?
Sí, pero el proceso es diferente. En proyectos existentes, el spec se usa para nuevas features o para refactorizaciones significativas. El ejercicio de escribir el spec de un módulo existente es también un audit implícito: si no puedes escribir el spec del módulo, es porque el módulo no tiene diseño coherente. El spec revela la deuda técnica que el código oculta.
¿SDD funciona con cualquier agente de IA o solo con Claude Code?
La metodología es agnóstica al agente. Spec.md, plan.md y tasks.md son documentos markdown que cualquier LLM puede usar como contexto. El skill /dominicode-sdd-spec-creator está diseñado para Claude Code y disponible en Dominicode Labs, pero los artefactos que genera son compatibles con cualquier entorno. Lo importante no es la herramienta — es el hábito de definir antes de ejecutar.
¿Qué pasa cuando el spec cambia durante el desarrollo? ¿No es todo ese trabajo en vano?
El spec cambia. Siempre cambia. Y eso es una funcionalidad, no un fallo. Cuando el spec cambia, tienes un documento que actualizar — y esa actualización fuerza una decisión consciente sobre el impacto del cambio en la arquitectura, los flujos y las tareas pendientes. Sin spec, el cambio ocurre de forma invisible: alguien pide algo diferente, el agente lo implementa, y nadie sabe qué asunciones antiguas quedan rotas. Con spec, el cambio es visible y gestionable.
¿Es SDD compatible con metodologías ágiles?
Completamente. SDD no impone un ciclo de desarrollo — impone un hábito de especificación antes de ejecución. Dentro de un sprint de dos semanas, el spec de las features del sprint se escribe al inicio. El plan.md define el orden de implementación dentro del sprint. El tasks.md genera los tickets concretos. SDD convierte el backlog en artefactos ejecutables para agentes, no en listas de deseos sin criterio técnico.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.