¿Qué es RALPH Loop? Guía técnica para arquitectos de agentes
Si buscas “que es ralph loop?” necesitas algo más que una definición: necesitas un mapa práctico para diseñar agentes que no se vuelvan peligrosos o caros en producción. El RALPH Loop es un patrón de control iterativo para agentes basados en LLM que añade aprendizaje y gobernanza explícita al ciclo de razonamiento-actuación. Aplicado bien, evita bucles infinitos, ahorra tokens y protege datos críticos. Aplicado mal, convierte tu agente en un script que consume presupuesto y arriesga integridad operacional.
Resumen rápido (lectores con prisa)
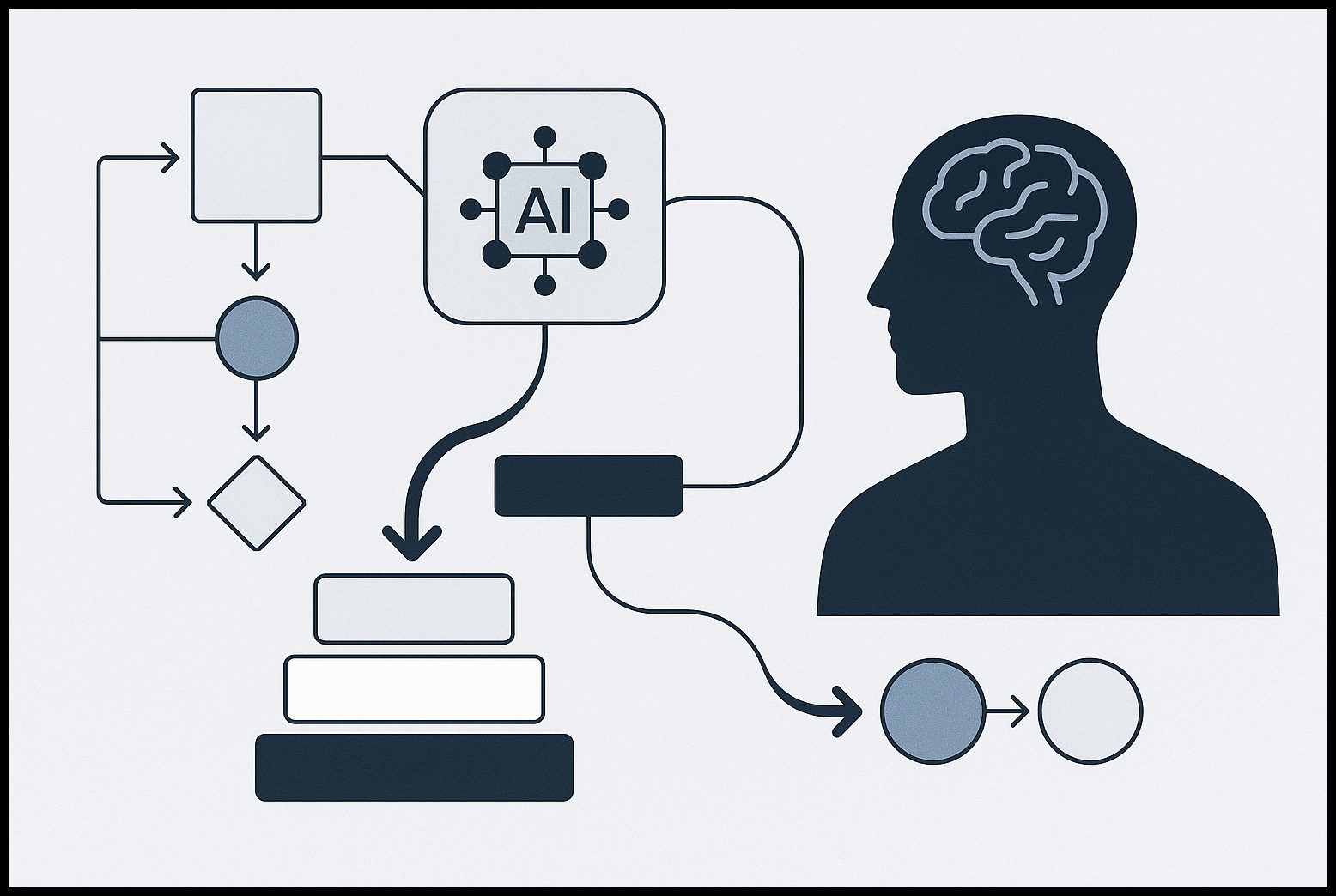
RALPH Loop organiza cada iteración del agente en cinco fases: Retrieve, Analyze/Act, Learn, Plan y Halt. Funciona combinando LLMs con memoria temporal y reglas deterministas para evitar bucles, reducir coste por tokens y proteger acciones destructivas. Se aplica cuando el agente tiene permisos de escritura, sesiones largas o herramientas múltiples; si no, ReAct o pipelines simples bastan.
Tiempo estimado de lectura: 4 min
Ideas clave
- Cinco fases: Retrieve, Analyze/Act, Learn, Plan, Halt.
- Halt crítico: combinación LLM + heurísticas deterministas (MaxSteps, token budget, detección de loops).
- Aprendizaje en ejecución: registrar resultados para no repetir errores en la misma sesión.
- Stacks recomendados: LangGraph/LangChain, n8n o implementación personalizada en Python.
- Checklist: sandboxing, trazas JSONL, límites y escalado humano.
Tabla de contenidos
- Título
- Resumen rápido (lectores con prisa)
- ¿Qué es RALPH Loop? Definición y motivación
- Las cinco fases del RALPH Loop (implementables)
- Por qué la fase Halt es la más crítica
- Implementación práctica: stacks y patrones
- Ejemplo concreto (simplificado)
- Cuándo aplicar RALPH Loop
- Checklist mínimo antes de desplegar
- Dominicode Labs
- FAQ
¿Qué es RALPH Loop? Definición y motivación
El RALPH Loop es un marco que organiza cada iteración del agente en cinco fases: Retrieve, Analyze/Act, Learn, Plan y Halt. Nace como evolución práctica de ReAct (Reason + Act) al responder a dos carencias claras en entornos reales: la incapacidad de aprender de acciones previas en la misma ejecución y la falta de una condición de parada robusta.
ReAct es un punto de partida académico útil (ver artículo de ReAct). RALPH toma esa base y la convierte en arquitectura productiva: trae memoria temporal, reglas deterministas y heurísticas de seguridad para que el agente no provoque incidentes.
Las cinco fases del RALPH Loop (implementables)
R: Retrieve (Recuperar)
– Recupera sólo el contexto necesario: historial relevante, resultados previos, vectores RAG. Evita saturar la ventana de contexto con ruido. Para RAG y vectores, mira prácticas comunes en Retrieval-Augmented Generation.
A: Analyze & Act (Analizar y Actuar)
– El LLM decide la herramienta y emite una llamada estructurada (function calling). Aquí la salida debe ser accionable (API call, ejecución de script, query SQL mockeada en pruebas).
L: Learn (Aprender)
– Registra el resultado (success/failure, códigos de error, latencia). Actualiza la memoria de trabajo para no repetir la misma acción inútil. Esta es la diferencia operativa: evita repetir fallos y detectar patrones de error.
P: Plan (Planificar)
– Ajusta la estrategia: intentar alternativa, degradar la acción, o solicitar más datos. Mantén un plan explícito serializable (lista de pasos pendientes, prioridad, contexto).
H: Halt (Detener/Escalar)
– Evaluación final: ¿objetivo cumplido? ¿sin progreso real? Si no, escalar a humano. La fase Halt combina la opinión del LLM con reglas duras (max steps, token budget, detección de loops).
Por qué la fase Halt es la más crítica
Los LLM son probabilísticos. No puedes confiar en que “sabran” cuando deben parar. En producción, la fase Halt se implementa como combinación LLM + heurísticas deterministas:
- Límite de iteraciones (MaxSteps = 5–15 según complejidad).
- Timeout absoluto por ejecución.
- Presupuesto de tokens/coste por ejecución.
- Detección de bucles semánticos (similitud coseno > 0.95 entre planes consecutivos).
- Reglas de seguridad para acciones destructivas (p. ej. bloqueo de
deletesin aprobación humana).
Estas reglas son guardrails; no sustituyen la auditoría humana, pero evitan incendios evitables.
Implementación práctica: stacks y patrones
LangGraph / LangChain
– Modela cada fase como nodo del grafo. Usa aristas condicionales en Halt que consulten métricas deterministas y el veredicto del LLM. Documentación útil para orquestación: Documentación de LangChain.
n8n
– Construye workflows cíclicos en lugar de un nodo monolítico de agente. Nodifica Retrieve, Analyze, Learn, Plan y un nodo Switch que implemente Halt. n8n facilita observabilidad y reintentos: n8n.
Implementación personalizada (Python)
– Clase AgentState serializable: historial, iteraciones, token_cost, last_action. Métodos: retrieve(), act(), learn(), plan(), halt_check(). Esto da máximo control y testabilidad.
Ejemplo concreto (simplificado)
Objetivo: “Optimizar consultas lentas”.
Iteración 1: Retrieve → identifica consulta y plan de índices.
Act: propone CREATE INDEX (mockeado en harness).
Learn: índice ya existe → error “duplicate”.
Plan: intenta analizar plan de ejecución alternativo.
Halt: si tras 5 intentos sigue sin progreso, escalar a humano.
Si CREATE INDEX hubiera sido ejecutado en prod sin harness, el agente podría seguir intentando acciones que dañan datos. RALPH previene eso.
Cuándo aplicar RALPH Loop
Usa RALPH cuando el agente:
- Tiene permisos de escritura o acciones con efectos irreversibles.
- Opera en sesiones largas con múltiples herramientas.
- Interactúa con APIs externas inestables o con datos sensibles.
Si tu caso es un simple extractor de texto o clasificación puntual, ReAct o un pipeline lineal bastan.
Checklist mínimo antes de desplegar
- Sandboxing y mocks para pruebas.
- Registro estructurado de trazas (JSONL).
- MaxSteps y token budget configurados.
- Mecanismo de escalado humano probado.
- Métricas: iteraciones por tarea, token cost, tasa de escalation.
El RALPH Loop no es magia; es disciplina de ingeniería. Si quieres agentes operables, dales memoria, reglas y límites. Sin eso, tendrás un asistente caro y peligroso. Con eso, tendrás una pieza automatizada que escala capacidad sin quemar infraestructura ni reputación.
Dominicode Labs
Si trabajas con automatización, agentes o workflows y quieres explorar patrones de producción y orquestación, consulta los recursos y experimentos disponibles en Dominicode Labs. Es una continuación lógica para equipos que buscan implementar guardrails y observabilidad en pipelines de agentes.
FAQ
- ¿Qué problemas resuelve RALPH Loop?
- ¿En qué se diferencia de ReAct?
- ¿Cuántas iteraciones debo permitir (MaxSteps)?
- ¿Cómo se detectan bucles semánticos?
- ¿Qué métricas debo registrar?
- ¿Es necesario usar un stack específico?
- ¿Cómo pruebo acciones destructivas en desarrollo?
¿Qué problemas resuelve RALPH Loop?
Evita bucles infinitos, reduce coste por tokens y protege la integridad operacional al añadir memoria temporal, aprendizaje en ejecución y reglas deterministas de parada.
¿En qué se diferencia de ReAct?
ReAct combina razonamiento y acción, pero no incorpora aprendizaje en la misma ejecución ni condiciones de parada robustas. RALPH añade fases de Learn y Halt para cubrir esas carencias.
¿Cuántas iteraciones debo permitir (MaxSteps)?
Depende de la complejidad: típicamente entre 5 y 15. Ajusta según riesgo, coste de tokens y criticidad de la acción.
¿Cómo se detectan bucles semánticos?
Usando métricas de similitud (por ejemplo, similitud coseno > 0.95 entre planes consecutivos) y comparando estados serializados del plan de acción.
¿Qué métricas debo registrar?
Iteraciones por tarea, token cost, latencia por acción, códigos de error, y tasa de escalado a humano.
¿Es necesario usar un stack específico?
No. LangGraph/LangChain y n8n son prácticas comunes por observabilidad y orquestación, pero una implementación personalizada en Python ofrece máximo control y testabilidad.
¿Cómo pruebo acciones destructivas en desarrollo?
Usa sandboxing y mocks, ejecuta acciones en harness controlado y registra resultados estructurados antes de permitir ejecuciones en producción.