Hace un par de años me tocó construir el buscador de un CRM interno. Filtros combinables por nombre, etiqueta, estado, rango de fechas, un par de campos personalizados que el cliente quería poder cruzar entre sí.
Nada del otro mundo. O eso pensé.
Me pasé una tarde entera peleando con un problema que HTTP, tal cual lo conocíamos hasta ahora, no resolvía bien. Spoiler: la solución llegó en 2026, se llama método HTTP QUERY, y llevaba más de veinte años de retraso.
¿Por qué una tarde entera por un simple buscador? Porque en cuanto diseñas el endpoint te topas con el mismo dilema de siempre.
El dilema de siempre: GET o POST
GET es la opción "correcta" semánticamente. No cambia nada en el servidor, se puede repetir sin miedo, y cualquier intermediario puede guardar la respuesta en caché.
El problema es práctico: en cuanto combinas más de cuatro o cinco filtros —arrays, rangos, objetos anidados— serializarlos en un query string se vuelve una tortura. Y las URIs tienen límites de tamaño reales, que servidores, proxies y CDNs aplican sin pedirte permiso.
Ahí es donde la mayoría termina en POST. Sin límite de tamaño relevante, acepta cualquier estructura en el body. Pero POST miente.
Le dice a cualquier intermediario —proxy, CDN, gateway— "esto modifica el estado del servidor, no lo cachees". Aunque tu POST /contacts/search solo esté leyendo datos.
El resultado: pierdes cacheo, pierdes la garantía de idempotencia que un retry automático podría necesitar, y terminas inventando convenciones como POST /contacts/_query para comunicar, solo con el nombre de la ruta y no con el protocolo, que en realidad es una lectura.
Yo terminé documentando en el README: "este POST es en realidad una consulta de solo lectura". Un parche humano para un problema que el protocolo debería resolver solo.
Cómo llegamos hasta aquí
En corto: HTTP no tuvo, durante veinte años, un método pensado para consultas complejas que fuera a la vez seguro, idempotente y cacheable — y la industria lo parcheó de mil formas distintas hasta que el RFC 10008 lo resolvió en 2026.
Este problema no es nuevo. Es viejo.
Las URIs de GET siempre tuvieron un techo práctico. No existe un límite en el estándar HTTP, pero servidores, proxies y navegadores lo imponen igual —y con diez o quince filtros combinables, lo tocas rápido.
La industria hizo lo que hace siempre ante un vacío del protocolo: usar POST para todo lo que GET no aguantaba. Búsquedas complejas, filtros anidados, exportaciones con parámetros, todo empaquetado en un body, aunque la operación fuera, en esencia, una lectura.
El coste de ese abuso semántico es real. Rompe el cacheo, porque los intermediarios no cachean POST por defecto. Rompe la idempotencia garantizada, porque un cliente no puede asumir que reintentar un POST es seguro. Y confunde a cualquier proxy o CDN que tome decisiones basadas en el método HTTP.
Hubo intentos de arreglarlo antes de 2026. WebDAV definió su propio método, SEARCH (RFC 5323), pensado para consultas complejas sobre colecciones de recursos. Nunca salió de su nicho.
Mientras tanto, herramientas que viven de resolver búsquedas complejas todos los días —Elasticsearch es el ejemplo obvio— no adoptaron SEARCH. Optaron por su propia convención, POST /_search, aceptando el mismo trade-off semántico que cualquiera de nosotros.
Veinte años de parches, cada uno resolviendo el síntoma, ninguno el problema de fondo: HTTP no tenía un método pensado para "quiero enviarte una consulta compleja, y quiero que sepas que es segura, idempotente y cacheable".
En 2026 el IETF lo estandarizó. El RFC 10008 —de Julian Reschke, James M. Snell y Mike Bishop, publicado como Proposed Standard— define el método QUERY exactamente para esto.
Qué es el método HTTP QUERY y cómo funciona
El RFC lo resume mejor que yo (traducción propia del original en inglés):
"El input de la operación query se pasa como contenido de la petición en vez de como parte de la URI de la petición. A diferencia de POST, sin embargo, el método es explícitamente seguro e idempotente."
QUERY toma la ventaja práctica de POST —el body, sin límites de tamaño relevantes, con soporte para estructuras complejas— y le devuelve las tres garantías semánticas que POST no ofrece:
- Seguro. No modifica el estado del recurso; un intermediario puede asumir que ejecutar la petición no tiene efectos secundarios.
- Idempotente. Puedes reintentar la misma petición todas las veces que necesites sin miedo a duplicar nada.
- Cacheable. La respuesta puede cachearse siguiendo las reglas estándar de HTTP caching, igual que un GET.
No es un detalle cosmético. Es lo que le permite a un proxy o una CDN cachear agresivamente sin arriesgarse a servir datos corruptos, porque el propio protocolo garantiza que la operación es de solo lectura.
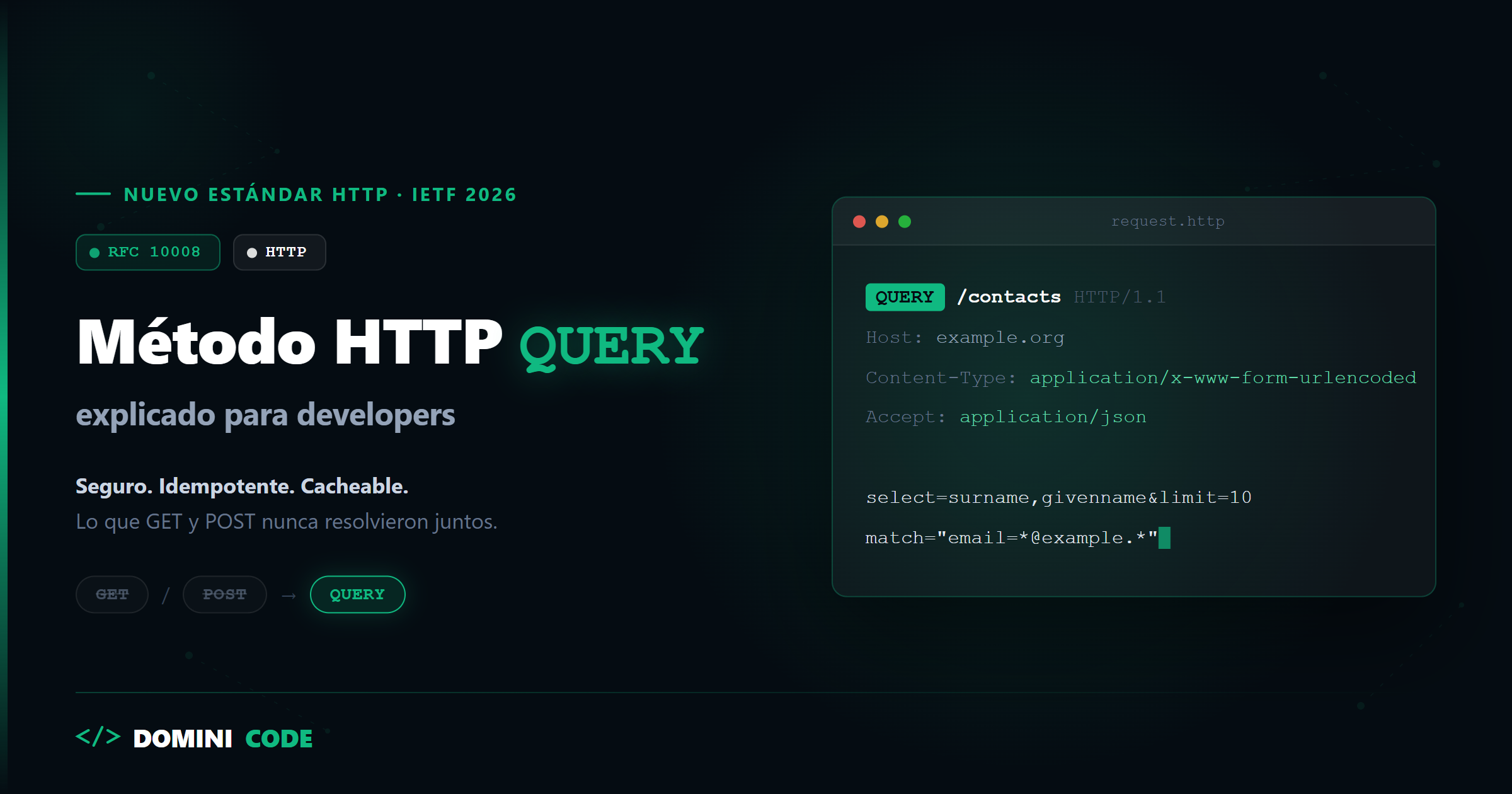
Así se ve una petición QUERY, tal cual la define el RFC:
QUERY /contacts HTTP/1.1
Host: example.org
Content-Type: application/x-www-form-urlencoded
Accept: application/json
select=surname,givenname&limit=10&match="email=*@example.*"
Línea por línea
QUERY /contacts— el verbo nuevo, apuntando al recurso de colección, igual que harías con GET.Content-Type— obligatorio. El servidor DEBE fallar la petición si el header falta o es inconsistente con el contenido real del body.Accept— content negotiation estándar para la respuesta.- El body —
select,limit,match— es donde vive la complejidad real de tu consulta, sin límites de URI ni arrays serializados en un query string.
(El body de este ejemplo está simplificado por legibilidad — en una petición application/x-www-form-urlencoded real, esos valores llevarían percent-encoding.)
El manejo de errores no deja ambigüedad. Si la petición no trae información suficiente sobre el media type, el servidor responde 400 Bad Request. Si el media type está identificado pero no es soportado, responde 415 Unsupported Media Type.
QUERY también soporta los condicionales HTTP que ya conoces —If-Modified-Since, If-None-Match— para re-consultar de forma eficiente sin traer de vuelta una respuesta que no cambió.
Si en tu backend ya validas y tipas los bodies de entrada, la lógica no cambia con QUERY: sigues necesitando un schema que valide select, limit y match antes de tocar tu capa de datos. QUERY no te libra de validar el input, solo te da un protocolo que comunica correctamente la intención. En el curso de Zod cubrimos justo este tipo de validación de bodies complejos con schemas tipados en TypeScript.
Cacheo y content negotiation: la parte que cambia las reglas
Con GET, la cache key es la URL. Punto.
Con QUERY no puede serlo, porque la consulta vive en el body. El RFC lo resuelve así: la cache key DEBE incorporar el contenido de la petición y su metadata relacionada. Las caches, eso sí, pueden normalizar diferencias semánticamente insignificantes —encoding, formato JSON con espacios distintos— para no fragmentar el cacheo por diferencias triviales.
Para que un recurso anuncie qué formatos de consulta soporta existe el header de respuesta Accept-Query, con sintaxis de Structured Fields. Es el equivalente a un Accept, pero para las capacidades de consulta del propio recurso.
Hay un detalle elegante más. Una respuesta 2xx a una QUERY puede incluir los headers Location o Content-Location apuntando a una URI equivalente:
Location: /contacts/stored-queries/42
Content-Location: /contacts/stored-results/17
Eso te permite guardar esa consulta —o su resultado— como un recurso direccionable por GET, sin reenviar el body completo cada vez que alguien quiera acceder al mismo resultado. El RFC es explícito en que esas URIs deberían elegirse de forma que no incluyan partes sensibles del contenido original de la petición.
El detalle que se te va a escapar: CORS
Esto es lo que casi nadie menciona cuando lee sobre QUERY por encima, y es justo lo que te va a morder si construyes APIs consumidas desde un frontend.
GET, POST y HEAD están en la lista de métodos "CORS-safelisted": el navegador puede dispararlos cross-origin sin pedir permiso primero. QUERY no está en esa lista.
Cualquier petición QUERY cross-origin dispara automáticamente un preflight: una petición OPTIONS previa donde el navegador le pregunta al servidor "¿me dejas hacer esto?" antes de ejecutar la petición real.
No es un bug ni una limitación del RFC. Es una decisión de seguridad del propio modelo CORS. Si vas a exponer un endpoint QUERY consumido desde un dominio distinto al de tu API, necesitas tener el preflight resuelto en tu configuración de CORS, o vas a ver peticiones fallando sin entender por qué — el día que tu stack te deje disparar una petición QUERY real desde el navegador. Ese nivel de soporte todavía no lo puedo confirmar, como explico un poco más abajo.
Qué significa esto en la práctica, hoy
En corto: sí puedes diseñar tu API con la semántica de QUERY desde ya, aunque el transporte real siga siendo POST mientras el soporte nativo del ecosistema madura.
Aquí toca ser honesto.
El RFC 10008 se publicó en 2026. Es un Proposed Standard del IETF —el sello más alto para un método nuevo— pero eso no significa que el ecosistema ya lo soporte de forma nativa en todas partes.
No tengo forma de confirmar, a la fecha de este post, qué nivel de soporte real tienen ya el fetch() de los navegadores o los frameworks de backend en Node —Express, NestJS, Hono— para este método. Es un estándar muy reciente y ese tipo de soporte cambia semana a semana. No me voy a inventar un dato que no puedo verificar.
Lo que sí puedes hacer hoy, con certeza, es diseñar tus endpoints con el modelo semántico correcto. Aunque el transporte real siga siendo POST por compatibilidad, puedes:
- Documentar que tu endpoint de búsqueda es una operación segura e idempotente, aunque use el verbo POST.
- Construir la cache key de tu capa de caché —Redis, CDN, lo que uses— incorporando el body completo, el mismo principio que usa QUERY.
- Exponer resultados reutilizables vía una URI propia, tu propio
Content-Locationcasero, para que un cliente pueda hacer GET después sin repetir la consulta.
Ese diseño no caduca. El día que tu framework soporte QUERY de forma nativa, migrar es un cambio de un verbo, porque la arquitectura ya estaba pensada correctamente.
Si tu backend está en NestJS, esta es exactamente el tipo de decisión de diseño de API que vale la pena resolver bien desde el controller. En el post sobre streaming con NestJS y el AI SDK de Vercel hablo de cómo estructurar endpoints que respetan la semántica HTTP correcta en vez de forzar todo por POST.
Del lado del frontend, si consumes estos endpoints desde Angular, la resource API introducida en v22 encaja con este modelo: una consulta segura y cacheable es exactamente el tipo de dato que quieres modelar como un resource reactivo, no como un efecto secundario disparado a mano. Lo cubro en el post sobre la resource API en Angular 22, y trabajamos el consumo de APIs con el Angular moderno —signals, resource, control flow— en el curso de Angular Moderno.
Hay un ángulo más que me parece el más interesante, y casi nadie lo está conectando todavía. Los agentes de IA que hacen tool-calling —vía MCP o cualquier otro protocolo— tienen el mismo problema que resolvimos hace veinte años con las APIs REST: un agente necesita saber, con certeza protocolar, si una tool que va a invocar es segura de reintentar o no.
QUERY le da a ese tipo de arquitecturas una semántica formal para "esto es una consulta, puedes cachearla, puedes reintentarla sin miedo". Es exactamente el tipo de diseño de herramientas que trabajamos en el curso de Construye con IA: que cada tool que expones a un agente tenga una semántica clara sobre sus efectos.
GET vs QUERY vs POST, en una tabla
| Aspecto | GET | QUERY | POST |
|---|---|---|---|
| Seguro | Sí | Sí | Potencialmente no |
| Idempotente | Sí | Sí | Potencialmente no |
| Query en la URI | Sí | Opcional* | No |
| Cacheable | Sí | Sí | Sí (limitado)** |
* Que el protocolo lo permita no significa que sea buena práctica: si vuelves a meter toda la consulta en la URI, pierdes la ventaja que motivó usar QUERY en primer lugar.
** Solo con headers de cache explícitos configurados a mano — no por defecto, como sí ocurre con GET y QUERY.
La tesis: esto no es una feature exótica
Llevábamos más de veinte años sin una respuesta oficial en el protocolo HTTP a una pregunta simple: ¿cómo hago una consulta compleja de forma segura, cacheable e idempotente?
No es que nadie lo necesitara. Es que cada quien lo parcheaba a su manera —convenciones de nombres, métodos no estándar, documentación humana explicando lo que el protocolo no podía comunicar solo.
QUERY no es HTTP inventando una feature exótica. Es HTTP poniéndose al día con un patrón que la industria ya necesitaba y ya estaba resolviendo, mal, de mil formas distintas.
Y esa es la parte que importa para tu trabajo diario: entender bien la semántica HTTP —qué es seguro, qué es idempotente, qué es cacheable— es una habilidad de arquitectura que trasciende cualquier framework. Angular, NestJS, Express, Hono van a cambiar. Los verbos y garantías de HTTP, no tanto.
Preguntas frecuentes sobre el método HTTP QUERY
¿Qué es el método HTTP QUERY?
Es un método HTTP nuevo, estandarizado en el RFC 10008 (IETF, Proposed Standard, 2026) por Julian Reschke, James M. Snell y Mike Bishop. Permite enviar el input de una consulta como contenido de la petición en vez de codificarlo en la URI, y a diferencia de POST, es explícitamente seguro, idempotente y cacheable.
¿QUERY reemplaza a POST para hacer búsquedas?
Reemplaza el uso de POST para operaciones de lectura que necesitan un body complejo: búsquedas, filtros combinados, consultas estructuradas. POST sigue siendo correcto para operaciones que sí modifican estado. El problema que QUERY resuelve es el abuso semántico de usar POST para leer datos, no el uso legítimo de POST para escribir.
¿Cuál es la diferencia entre el método QUERY y POST en HTTP?
La diferencia no es de capacidad —ambos aceptan un body con estructuras complejas— sino de las garantías que cada método comunica al resto de la infraestructura HTTP. POST no promete que la operación sea segura ni idempotente, así que ningún proxy o CDN puede asumirlo ni cachearla por defecto. QUERY sí lo garantiza explícitamente: es seguro, idempotente y cacheable, igual que GET, pero sin los límites de una URI.
¿Ya puedo usar el método QUERY en producción hoy?
Con cautela. El RFC se publicó en 2026 y es muy reciente —no hay forma de confirmar en este momento qué nivel de soporte nativo tienen ya los navegadores (fetch()) o los frameworks de backend más usados en Node. Lo prudente es diseñar tus endpoints con la semántica correcta de QUERY aunque sigas transportándolos con POST mientras el soporte nativo del ecosistema madura.
¿Cómo se cachea una petición QUERY si la consulta no está en la URL?
La cache key deja de basarse solo en la URL, como con GET, y debe incorporar el contenido completo de la petición y su metadata relacionada. Las caches pueden normalizar diferencias semánticamente insignificantes —como el encoding o el formato del JSON— para no fragmentar el cacheo innecesariamente.
¿Qué diferencia hay entre QUERY y el método SEARCH de WebDAV?
SEARCH (RFC 5323) fue un intento anterior, específico de WebDAV, para consultas complejas sobre colecciones de recursos, y nunca tuvo adopción fuera de ese nicho. QUERY es un método de propósito general, estandarizado en el núcleo de HTTP —no atado a una extensión como WebDAV—, con reglas explícitas de content negotiation, cacheo y manejo de errores que SEARCH nunca definió con ese nivel de detalle.
¿Por qué una petición QUERY cross-origin necesita un preflight?
Porque QUERY no está en la lista de métodos "CORS-safelisted", a diferencia de GET, POST y HEAD. Cualquier método fuera de esa lista obliga al navegador a enviar una petición OPTIONS previa —el preflight— para confirmar que el servidor permite esa petición antes de ejecutarla.
Por Bezael Pérez — Developer senior con más de 15 años de experiencia y fundador de Dominicode.